
R??gression lin??aire
?? propos de ce ??coles s??lection Wikipedia
SOS Enfants, un organisme de bienfaisance de l'??ducation , a organis?? cette s??lection. Une bonne fa??on d'aider d'autres enfants est de parrainer un enfant
R??gression lin??aire est une forme d' analyse de r??gression dans lequel les donn??es d'observation sont mod??lis??s par un des moindres carr??s fonction qui est un combinaison lin??aire des param??tres du mod??le et d??pend d'un ou plusieurs variables ind??pendantes. Dans la r??gression lin??aire simple la fonction de mod??le repr??sente une ligne droite. Les r??sultats de l'ajustement des donn??es sont soumises ?? une analyse statistique.

D??finitions
Les donn??es sont des valeurs de m 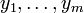 pris ?? partir d'observations de la variable d??pendante ( variable de r??ponse)
pris ?? partir d'observations de la variable d??pendante ( variable de r??ponse) 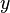 . La variable d??pendante est sujette ?? l'erreur. Cette erreur est suppos??e ??tre variable al??atoire , avec une moyenne de z??ro. L'erreur syst??matique (par exemple signifie ≠ 0) peut ??tre pr??sent, mais son traitement est en dehors de la port??e de l'analyse de r??gression. La variable ind??pendante ( variable explicative)
. La variable d??pendante est sujette ?? l'erreur. Cette erreur est suppos??e ??tre variable al??atoire , avec une moyenne de z??ro. L'erreur syst??matique (par exemple signifie ≠ 0) peut ??tre pr??sent, mais son traitement est en dehors de la port??e de l'analyse de r??gression. La variable ind??pendante ( variable explicative)  , Est sans erreur. Si ce ne est pas le cas, la mod??lisation devrait ??tre fait en utilisant erreurs dans les variables de techniques de mod??le. Les variables ind??pendantes sont ??galement appel??es variables explicatives, les variables exog??nes, les variables d'entr??e et des variables pr??dictives. Dans la r??gression lin??aire simple du mod??le de donn??es est ??crit comme
, Est sans erreur. Si ce ne est pas le cas, la mod??lisation devrait ??tre fait en utilisant erreurs dans les variables de techniques de mod??le. Les variables ind??pendantes sont ??galement appel??es variables explicatives, les variables exog??nes, les variables d'entr??e et des variables pr??dictives. Dans la r??gression lin??aire simple du mod??le de donn??es est ??crit comme

o?? 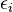 est une erreur d'observation.
est une erreur d'observation. 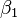 (Interception) et
(Interception) et 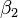 (Pente) sont les param??tres du mod??le. En g??n??ral, il ya n param??tres,
(Pente) sont les param??tres du mod??le. En g??n??ral, il ya n param??tres, 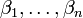 et le mod??le peut se ??crire
et le mod??le peut se ??crire
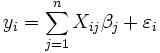
o?? les coefficients 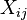 sont des constantes ou des fonctions de la variable ind??pendante, x. Les mod??les qui ne sont pas conformes ?? cette sp??cification doivent ??tre trait??s par r??gression non lin??aire.
sont des constantes ou des fonctions de la variable ind??pendante, x. Les mod??les qui ne sont pas conformes ?? cette sp??cification doivent ??tre trait??s par r??gression non lin??aire.
Sauf indication contraire, on suppose que les erreurs d'observation sont d??corr??l??es et appartiennent ?? une distribution normale . Ce, ou une autre hypoth??se, est utilis?? lors de l'ex??cution des tests statistiques sur les r??sultats de la r??gression. Une formulation ??quivalente de r??gression lin??aire simple qui montre explicitement la r??gression lin??aire comme un mod??le de l'esp??rance conditionnelle peut ??tre donn??e quant
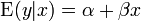
Le distribution conditionnelle de y x donn??e est une transformation lin??aire de la distribution du terme d'erreur.
Notation et conventions de nommage
- Scalaires et vecteurs sont d??sign??s par des lettres minuscules.
- Matrices sont d??sign??s par des lettres majuscules.
- Les param??tres sont d??sign??es par des lettres grecques.
- Vecteurs et les matrices sont d??sign??s par des lettres en gras.
- Un param??tre avec un chapeau, comme
 , D??signe un estimateur de param??tre.
, D??signe un estimateur de param??tre.
L'analyse des moindres carr??s
Le premier objectif de l'analyse de r??gression est de mieux adapter les donn??es en ajustant les param??tres du mod??le. Parmi les diff??rents crit??res qui peuvent ??tre utilis??s pour d??finir ce qui constitue un meilleur ajustement, le crit??re des moindres carr??s est tr??s puissant. La fonction objectif, S, est d??fini comme la somme des carr??s des r??sidus, r i
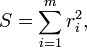
o?? chaque r??siduelle est la diff??rence entre la valeur observ??e et la valeur calcul??e par le mod??le:

Le meilleur ajustement est obtenu lorsque S, la somme des carr??s des r??sidus, est minimis??e. Sous r??serve de certaines conditions, les param??tres ont ensuite minimum variance ( Th??or??me de Gauss-Markov) et peuvent aussi repr??senter un solution du maximum de vraisemblance pour le probl??me d'optimisation.
De la th??orie de lin??aires des moindres carr??s, les estimateurs de param??tres sont trouv??es en r??solvant les ??quations normales
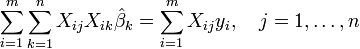
En notation matricielle, ces ??quations sont ??crites en tant que
 ,
,
Et ce est ainsi lorsque la matrice 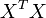 est non singuli??re:
est non singuli??re:
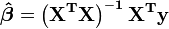 ,
,
Plus pr??cis??ment, pour le montage lin??aire, cela est indiqu?? dans raccord de ligne droite.
les statistiques de r??gression
Le deuxi??me objectif de r??gression est l'analyse statistique des r??sultats de l'ajustement des donn??es.
Notons 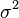 la variance du terme d'erreur
la variance du terme d'erreur  (De sorte que
(De sorte que 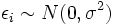 pour chaque
pour chaque 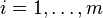 ). Une estimation non biais??e de est donn??e par
). Une estimation non biais??e de est donn??e par
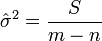 .
.
La relation entre l'estimation et la valeur r??elle est:
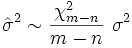
o?? 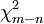 a la distribution chi carr?? avec
a la distribution chi carr?? avec 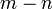 degr??s de libert??.
degr??s de libert??.
L'application de ce crit??re exige que , La variance d'une observation de poids unitaire, ??tre estim??e. Si le 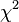 Le test est pass??, les donn??es peuvent ??tre dit ?? ??tre mont?? ?? l'int??rieur erreur d'observation.
Le test est pass??, les donn??es peuvent ??tre dit ?? ??tre mont?? ?? l'int??rieur erreur d'observation.
La solution des ??quations normales peut se ??crire
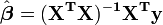
Cela montre que les estimateurs de param??tres sont des combinaisons lin??aires de la variable d??pendante. Il se ensuit que, si les erreurs d'observation sont normalement distribu??es, les estimateurs de param??tres seront appartenir ?? un la distribution t de Student avec degr??s de libert??. L' ??cart-type sur un estimateur de param??tres est donn??e par
![\ Hat \ sigma_j = \ sqrt {\ frac {S} {mn} \ left [\ mathbf {(X ^ TX)} ^ {- 1} \ right] _ {}} jj](../../images/216/21697.png)
Le 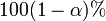 intervalle de confiance pour le param??tre,
intervalle de confiance pour le param??tre, 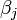 , Est calcul??e comme suit:
, Est calcul??e comme suit:
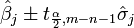
Les r??sidus peuvent ??tre exprim??es comme
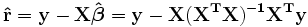
La matrice 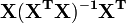 qui est connu comme le matrice chapeau et a la propri??t?? utile qui il est idempotent. En utilisant cette propri??t??, il peut ??tre d??montr?? que, si les erreurs sont normalement distribu??es, les r??sidus suivront un la distribution t de Student avec degr??s de libert??. Studentis??s r??sidus sont utiles dans les tests pour aberrantes.
qui est connu comme le matrice chapeau et a la propri??t?? utile qui il est idempotent. En utilisant cette propri??t??, il peut ??tre d??montr?? que, si les erreurs sont normalement distribu??es, les r??sidus suivront un la distribution t de Student avec degr??s de libert??. Studentis??s r??sidus sont utiles dans les tests pour aberrantes.
Compte tenu de la valeur de la variable ind??pendante, x d, la r??ponse pr??dite est calcul??e comme

??crit les ??l??ments  comme
comme  , Le intervalle de confiance de r??ponse signifie pour la pr??diction est donn??e, en utilisant th??orie de la propagation de l'erreur, par:
, Le intervalle de confiance de r??ponse signifie pour la pr??diction est donn??e, en utilisant th??orie de la propagation de l'erreur, par:
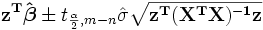
Le les intervalles de confiance de r??ponse pr??dites pour les donn??es sont donn??es par:
 .
.
Cas lin??aire
Dans le cas o?? la formule ?? ??quiper est une ligne droite, 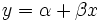 Les ??quations normales sont
Les ??quations normales sont
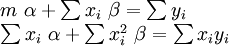
o?? toutes les sommations sont de i = 1 ?? i = m. De l??, par La r??gle de Cramer,
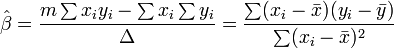
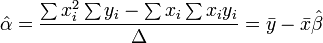
o??
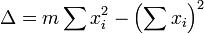
La matrice de covariance est
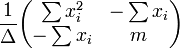
Le signifie intervalle de confiance de r??ponse est donn??e par

Le pr??voir un intervalle de confiance de la r??ponse est donn??e par
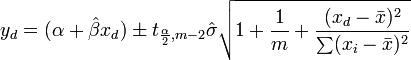
Analyse des ??carts
L'analyse de variance est similaire ?? ANOVA en ce que la somme des carr??s des r??sidus se d??compose en deux composantes. La somme des carr??s de r??gression (ou la somme des carr??s des r??sidus) SSR (aussi commun??ment appel?? RSS) est donn?? par:
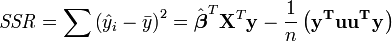
o?? 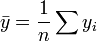 et u est un n par une unit?? vecteur (ce est ?? dire chaque ??l??ment est 1). Notez que les termes
et u est un n par une unit?? vecteur (ce est ?? dire chaque ??l??ment est 1). Notez que les termes 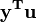 et
et  sont tous deux ??quivalents ??
sont tous deux ??quivalents ?? 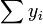 , Et ainsi le terme
, Et ainsi le terme 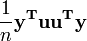 est ??quivalent ??
est ??quivalent ??  .
.
L'erreur (ou inexpliqu??e) somme des carr??s ESS est donn?? par:
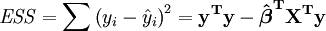
La somme totale des carr??s est donn??e par TSS

Le coefficient de Pearson de la r??gression, R ?? est alors donn??e comme
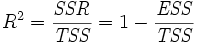
Exemple
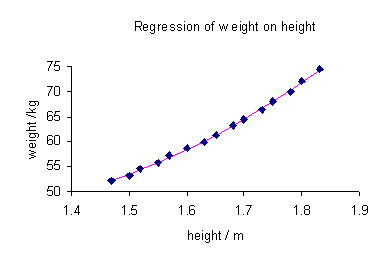
Pour illustrer les diff??rents objectifs de la r??gression, nous donnons un exemple. L'ensemble de donn??es suivant donne les hauteurs moyennes et les poids pour les femmes am??ricaines de 30 ?? 39 (source: Le World Almanac and Book des faits, 1975) ??g??s.
Hauteur / m 1,47 1,5 1,52 1,55 1,57 1,60 1,63 1,65 1,68 1,7 1,73 1,75 1,78 1,8 1,83 Poids / kg 52,21 53,12 54,48 55,84 57,2 58,57 59,93 61,29 63,11 64,47 66,28 68,1 69,92 72,19 74,46
Une parcelle de poids contre la hauteur (voir ci-dessous) montre qu'il ne peut pas ??tre mod??lis??e par une ligne droite, donc une r??gression est effectu??e en mod??lisant les donn??es par une parabole.
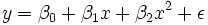
o?? la variable d??pendante, y, est le poids et la variable ind??pendante, x est la hauteur.
Placez les coefficients, 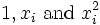 , Des param??tres de la i ??me ??me observation dans la ligne i de la matrice X.
, Des param??tres de la i ??me ??me observation dans la ligne i de la matrice X.
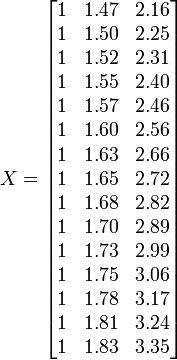

Les valeurs des param??tres sont trouv??es en r??solvant les ??quations normales

??l??ment ij de la matrice de l'??quation normale,  est form?? en additionnant les produits de la colonne i et la colonne j de X.
est form?? en additionnant les produits de la colonne i et la colonne j de X.
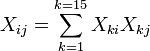
??l??ment i du vecteur de droite 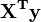 est form?? en additionnant les produits de la colonne i de X avec la colonne de valeurs de variables ind??pendantes.
est form?? en additionnant les produits de la colonne i de X avec la colonne de valeurs de variables ind??pendantes.
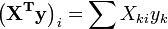
Ainsi, les ??quations normales sont
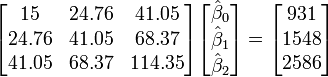
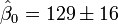 (Valeur
(Valeur 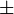 ??cart-type)
??cart-type) 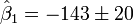
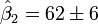
Les valeurs calcul??es sont donn??s par

Les donn??es observ??es et calcul??es sont trac??es ensemble et les r??sidus, 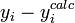 , Sont calcul??s et trac??s. Les ??carts-types sont calcul??s en utilisant la somme des carr??s,
, Sont calcul??s et trac??s. Les ??carts-types sont calcul??s en utilisant la somme des carr??s,  .
.
Les intervalles de confiance sont calcul??s en utilisant:
![[\ Hat {\ beta_j} - \ sigma_j t_ {mn; 1- \ frac {\ alpha} {2}}; \ hat {\ beta_j} + \ sigma_j t_ {mn; 1- \ frac {\ alpha} {2 }}]](../../images/217/21747.png)
avec  = 5%,
= 5%, 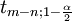 = 2,2. Par cons??quent, nous pouvons dire que les 95% intervalles de confiance sont:
= 2,2. Par cons??quent, nous pouvons dire que les 95% intervalles de confiance sont:
![\ Beta_0 \ in [92.9,164.7]](../../images/217/21749.png)
![\ Beta_1 \ in [-186,8, -99,5]](../../images/217/21750.png)
![\ Beta_2 \ in [48.7,75.2]](../../images/217/21751.png)
{kind=link}
V??rifier les hypoth??ses du mod??le
Les hypoth??ses du mod??le sont v??rifi??es par calcul des r??sidus et de les tracer. Les parcelles suivantes peuvent ??tre construits pour tester la validit?? des hypoth??ses:
- R??sidus contre la variable explicative, comme illustr?? ci-dessus.
- Un temps de terrain s??rie de r??sidus, ce est-?? tracer les r??sidus en tant que fonction du temps.
- R??sidus contre les valeurs ajust??es,
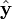 .
. - Les r??sidus r??siduelle contre le pr??c??dent.
- Un trac?? de probabilit?? normale des r??sidus de tester la normalit??. Les points doivent se situer le long d'une ligne droite.
Il ne devrait pas y avoir de motif sensible aux donn??es de tous, mais la derni??re parcelle
V??rification de la validit?? du mod??le
La validit?? du mod??le peut ??tre v??rifi??e en utilisant l'une des m??thodes suivantes:
- Utilisation de l'intervalle de confiance pour chacun des param??tres, . Si l'intervalle de confiance comprend 0, le param??tre peut ??tre retir?? ?? partir du mod??le. Id??alement, une nouvelle analyse de r??gression excluant ce param??tre serait n??cessaire d'effectuer et a continu?? jusqu'?? ce qu'il n'y a plus de param??tres ?? supprimer.
- Lors du montage d'une ligne droite, calculer le coefficient de Pearson de r??gression. Plus la valeur est de 1; meilleure est la r??gression est. Ce coefficient donne ce fraction du comportement observ?? peut ??tre expliqu?? par les variables donn??es.
- Examiner les intervalles de confiance d'observation et de pr??vision. Plus elles sont le mieux.
- Le calcul de la F-statistiques.
D'autres proc??dures
Pond??r??es moindres carr??s
Pond??r??es moindres carr??s est une g??n??ralisation de la m??thode des moindres carr??s, utilis??e lorsque les erreurs d'observation ont une variance in??gale.
Mod??le erreurs dans les variables
Mod??le erreurs dans les variables ou les moindres carr??s totale lorsque la variable ind??pendante est sujette ?? l'erreur
Mod??le lin??aire g??n??ralis??
Mod??le lin??aire g??n??ralis?? est utilis?? lorsque la fonction de distribution des erreurs ne est pas une distribution normale. Les exemples incluent la distribution exponentielle , la distribution gamma, La distribution gaussien inverse, distribution de Poisson , loi binomiale , distribution multinomiale
R??gression robuste
Une foule d'autres approches pour le calcul des param??tres de r??gression sont inclus dans la cat??gorie dite r??gression robuste. Une technique minimise la moyenne erreur absolue, ou une autre fonction des r??sidus, au lieu de l'erreur quadratique moyenne comme dans la r??gression lin??aire. R??gression robuste est beaucoup plus de calculs que la r??gression lin??aire et est un peu plus difficile ?? mettre en ??uvre ainsi. Bien que les estimations des moindres carr??s ne sont pas tr??s sensibles ?? la rupture de la normalit?? de l'hypoth??se des erreurs, ce ne est pas vrai quand la variance ou moyenne de la distribution d'erreur ne est pas born??, ou quand un analyste qui permet d'identifier les valeurs aberrantes ne est pas disponible.
Entre Utilisateurs Stata, la r??gression robuste est souvent pris pour signifier r??gression lin??aire avec les estimations de l'erreur type de Huber-White en raison des conventions de nommage pour les commandes de r??gression. Cette proc??dure assouplit l'hypoth??se de homosc??dasticit?? estimations de la variance pour seulement; les pr??dicteurs sont encore moindres carr??s ordinaires (MCO) des estimations. Cela conduit parfois ?? la confusion; Stata utilisateurs croient parfois que la r??gression lin??aire est une m??thode robuste lorsque cette option est utilis??e, m??me si elle ne est pas r??ellement robuste dans le sens de la valeur aberrante r??sistance.
Applications de r??gression lin??aire
R??gression lin??aire est largement utilis?? dans les sciences biologiques, comportementales et sociales pour d??crire les relations entre les variables. Il est class?? comme l'un des outils les plus importants utilis??s dans ces disciplines.
La ligne de tendance
Une ligne de tendance repr??sente une tendance, le mouvement ?? long terme des donn??es de s??ries chronologiques apr??s d'autres composants ont ??t?? comptabilis??es. Il indique si un ensemble de donn??es particulier (disons PIB, des prix du p??trole ou des prix d'achat d'actions) ont augment?? ou diminu?? au cours de la p??riode de temps. Une ligne de tendance pourrait ??tre simplement dessin??e par ??il ?? travers un ensemble de points de donn??es, mais plus correctement leur position et la pente est calcul??e en utilisant des techniques statistiques comme la r??gression lin??aire. Les lignes de tendance sont g??n??ralement des lignes droites, bien que certaines variations utilisent des polyn??mes de degr?? plus ??lev?? selon le degr?? de courbure d??sir??e dans la ligne.
Les lignes de tendance sont parfois utilis??s en analyse d'affaires pour montrer les changements dans les donn??es au fil du temps. Ceci a l'avantage d'??tre simple. Les lignes de tendance sont souvent utilis??s pour faire valoir qu'une action particuli??re ou un ??v??nement (comme la formation, ou une campagne de publicit??) ont caus?? les changements observ??s ?? un moment donn??. Ce est une technique simple, et ne n??cessite pas un groupe de contr??le, la conception exp??rimentale, ou une technique d'analyse sophistiqu??s. Cependant, il souffre d'un manque de validit?? scientifique dans les cas o?? d'autres changements potentiels peuvent affecter les donn??es.
M??decine
?? titre d'exemple, des signes pr??coces concernant le tabagisme ?? la mortalit?? et la morbidit?? provenaient d'??tudes employant r??gression. Les chercheurs comprennent g??n??ralement plusieurs variables dans leur analyse de r??gression dans un effort pour ??liminer les facteurs qui pourraient produire corr??lations parasites. Pour l'exemple de la cigarette, les chercheurs pourraient inclure le statut socio-??conomique, en plus de fumer pour se assurer que tout effet du tabagisme sur la mortalit?? observ??e ne est pas due ?? un effet de l'??ducation ou de revenu. Cependant, il ne est jamais possible d'inclure toutes les variables de confusion possibles dans une ??tude utilisant la r??gression. Pour l'exemple de fumer, un g??ne hypoth??tique pourrait augmenter la mortalit?? et aussi inciter les gens ?? fumer davantage. Pour cette raison, essais contr??l??s randomis??s sont consid??r??s comme plus fiables que d'une analyse de r??gression.
Financement
Le mod??le capital asset pricing utilise r??gression lin??aire ainsi que le concept de Beta pour analyser et quantifier le risque syst??matique d'un investissement. Cela vient directement du Coefficient b??ta du mod??le de r??gression lin??aire qui concerne le retour sur l'investissement pour le retour sur tous les actifs risqu??s.
R??gression peut ne pas ??tre le moyen appropri?? pour estimer beta dans la finance ??tant donn?? qu'il est cens?? fournir la volatilit?? d'un investissement par rapport ?? la volatilit?? du march?? dans son ensemble. Il faudrait pour cela que ces deux variables sont trait??s de la m??me fa??on lors de l'estimation de la pente. Consid??rant que la traite r??gression tous comme ??tant la variabilit?? dans l'investissement des rendements variables, ?? savoir qu'il ne consid??re r??sidus dans la variable d??pendante.