
{kind=link}
Apostrophe (typographie)
| Apostrophe | |
’ ' ʼ
| |
| Graphies | |
|---|---|
| Graphie | ’ ' ʼ |
| Codage | |
| Noms | guillemet-apostrophe (recommandée), apostrophe (à usages variés), lettre apostrophe |
| Unicode | U+2019 U+0027 U+02BC |
| Blocs | Ponctuation générale Commandes C0 et latin de base Lettres modificatives avec chasse |
| modifier | |
L’apostrophe est un signe typographique de ponctuation, un diacritique, voire une lettre. Issue d’une ponctuation de l’alphabet grec qui indique l’élision, elle a été empruntée par d’autres écritures, dont l’alphabet latin principalement.
Aspect

L’apostrophe a traditionnellement la forme d’une virgule placée en hauteur. On retrouve déjà cette définition d’« une virgule que l’on met un peu au-dessus du mot » dès la première édition du Dictionnaire de l'Académie française (1694)[1] et plus récemment chez Jean-Pierre Lacroux : « Une virgule libérée de la pesanteur qui la clouait sur la ligne de base »[2]. En allemand, dans le langage courant ou populaire, elle est nommée Hochkomma, littéralement « virgule haute ».
En raison des contraintes techniques des claviers de machines à écrire, puis de nos jours de ceux des ordinateurs, elle est très souvent tracée comme une barre verticale droite dans les documents informatiques. Cette apostrophe est alors appelée « apostrophe dactylographique » (car apparue avec les machines à écrire mécaniques utilisant une seule touche pour l’apostrophe et le guillemet anglais ouvrant ou fermant, ou même d’autres signes comme l’accent aigu), « apostrophe droite » (car elle est souvent droite pour le guillemet anglais ouvrant ou fermant, mais pas toujours), apostrophe informatique[3] ou d’autres noms plus imagés[4]. Les expressions « apostrophe dactylographique » et « apostrophe typographique » sont utilisées par Aurel Ramat[5].
Selon les usages des typographes, l’apostrophe dactylographique ne devrait pas être employée[6],[7] et, par exemple, pour Lacroux, ce « n’est pas une apostrophe. […] Ce n’est typographiquement rien »[2].
L’apostrophe est généralement courbe et plus ou moins inclinée : de nombreuses polices de caractères la représentent par une barre oblique. Unicode distingue bien les différents œils de l’apostrophe ainsi que ses différentes fonctions : signe typographique de ponctuation, signe diacritique ou lettre. Il recommande d’utiliser le guillemet-apostrophe « ’ » (U+2019) comme apostrophe typographique[8],[9]. Patrick Andries, expert Unicode, fait la même recommandation[10]. Le caractère apostrophe dactylographique hérité de l’ASCII conserve les sens qu’il a dans ce codage, c’est-à-dire « apostrophe, guillemet anglais fermant, accent aigu »[11] ; le caractère guillemet-apostrophe, recommandé pour l’apostrophe, ayant été codé pour enlever certaines ambigüités[12].
Signes proches

Il existe plusieurs signes qui, bien que proches de l’apostrophe, ne devraient pas être confondus avec elle. Il est fréquent qu’on emploie, dans une composition typographique moins appliquée, l’apostrophe au lieu d’un demi-anneau à droite dans la transcription des langues sémitiques. L’utilisation d’une apostrophe « droite » est à déconseiller car il existe pour la transcription de ces langues deux consonnes qu’on note par les demi-anneaux, l’un tourné à droite, l’autre à gauche : l’apostrophe droite ne permet plus de différencier les deux. Ainsi, شَيْء [ʃajʔ], « chose » (arabe), peut être transcrit šayʾ (anneau à droite) ou, moins conseillé, šay’ (apostrophe) mais, de préférence, pas šay' (apostrophe droite), qui ne permet pas de savoir si l’on a affaire à la consonne [ʔ], notée par ʾ (parfois remplacée par ’) ou à ʿ (anneau à gauche, parfois remplacé par ‘, une apostrophe culbutée), notant [ʕ] (selon l’analyse traditionnelle ; on peut voir dans l’article phonologie de l’arabe que le cas est plus complexe).
À l’inverse, l’okina hawaïenne, une apostrophe culbutée, note bien un coup de glotte. Enfin, on utilise pour l’alphabet phonétique international une ligne verticale courte en hauteur proche de l’apostrophe droite précédant la syllabe portant un accent tonique (il existe aussi une ligne verticale basse, mais qu’on ne peut confondre avec une apostrophe).
Histoire
L’apostrophe est initialement un signe diacritique de l’alphabet grec[13], qui a donné naissance à un diacritique de cet alphabet, la corônis, de forme similaire, indiquant la crase (contraction de deux voyelles en hiatus entre deux mots liés par le sens). On le retrouve en latin populaire et notamment dans des manuscrits de Virgile ou Priscien[13]. Selon Weil et Benloew, il aurait évolué à partir du sicilicus pour indiquer une lettre supprimée[14]. Au Moyen Âge, il apparaît en ancien français, par exemple dans le roman manuscrit Lancelot ou Chevalier de la charrette de Chrétien de Troyes vers 1180 ; et au xve siècle[15] dans la première grammaire italienne, aussi en manuscrit, Regole della lingua fiorentina de Leon Battista Alberti[13].
En imprimerie, la première utilisation de l’apostrophe remonte au XVIe siècle en Italie. Alde Manuce l’utilise en 1501 dans l’ouvrage Le cose volgari di messer Francesco Petrarcha[13],[16]. En France, Balthazard de Gabiano l’utilisera à Lyon dès 1502, et Geoffroy Tory l’utilisera de manière anecdotique en 1529 puis systématique en 1533[13]. En Angleterre, il faut attendre 1559 pour que William Cunninghams l’emploie dans The Cosmographical Glasse[13].
L’adoption de l’apostrophe dans l’imprimerie se fait donc relativement rapidement. Aussi rapidement les grammairiens recommandent son utilisation. Jacques Dubois, dit Jacobus Sylvius, publie en 1532 une grammaire en latin nommée In linguam gallicam isagoge préconisant l’usage de l’apostrophe pour l’élision. Étienne Dolet puis Robert Estienne feront de même en 1540 et 1569[13].
Sa pratique s’élargit au XVIe et XVIIe siècles puis connaît un recul progressif de ses domaines d’application qui sont actuellement relativement restreints[17].
En français
C’est en français que l’apostrophe est la plus fréquente[18] :
| Langue | Français | Italien | Anglais | Allemand | Espagnol |
|---|---|---|---|---|---|
| Nombre d’apostrophes | 10000 | 6000 | 500 | Quelques-unes | Quelques-unes |
| Nombre de points de fin de phrase | 9000 | 9000 | 9000 | 9000 | 9000 |
Élision
En français, l’apostrophe sert de signe typographique marquant l’élision des voyelles finales a et e de certains mots, et i pour ce qui est de la conjonction si suivie du pronom il[19]. L’élision se fait lorsque ces mots sont suivis d'un mot commençant par une voyelle ou un h muet. Ainsi on a : la + apostrophe → l’apostrophe, le + oiseau → l’oiseau, si + il → s’il, que + elle/il → qu’elle/qu’il, presque + île → presqu’île, le + homme → l’homme, le + hôtel → l’hôtel, le + hôpital → l’hôpital. Dans le langage populaire, l’élision de la voyelle finale i du pronom relatif sujet qui est aussi représentée par l’apostrophe par certains auteurs[19], et, dans le langage familier, pour l’élision de la voyelle finale u du pronom personnel tu[19]. Par exemple : qui est → qu’est en langage populaire, tu es → t’es en langage familier. L'élision peut aussi porter sur une partie du mot, en particulier pour restituer certaines prononciations populaires défectueuses. Par exemple pauvre con → pauv' con.
En ce qui concerne les mots commençant par un h, il est nécessaire de savoir s’il est muet ou aspiré. Avec les mots commençant par un h aspiré, l’élision ne se fait pas et par conséquent on n’utilise pas d’apostrophe. Ainsi on a : la haie, le haricot, la hâte, le hibou, la housse, la hutte, etc. L’apostrophe n’est qu’une marque de confort, tant à l’oral qu’à la lecture. Cet usage, très courant en français, s’applique seulement à certains mots, le plus souvent monosyllabiques. Toutefois, l’emploi de l’apostrophe n'est pas seulement permis dans certaines circonstances, mais obligatoire : *« je te ai dit que il me aimait » est fautif. On doit dire et écrire : « je t’ai dit qu’il m’aimait ».
Des mots dont la voyelle finale peut être élidée incluent :
- Les mots monosyllabiques : le, la, de, je, me, te, se, ce, ne, que, de même que la conjonction si, uniquement lorsque celle-ci est suivie du pronom sujet il.
- Autres mots et locutions : jusque, lorsque, puisque, quelque, quoique, parce que, quoi que, tel(le) que.
L’élision du e muet final n’est pas soulignée par l’apostrophe dans les autres cas. On écrit en effet la cuisine est vaste et lumineuse.
Quelques mots notables ne pouvant être précédés d’une apostrophe incluent (dont l’élision ne peut se faire devant) :
- huit, huitième, onze, onzième, un (seulement lorsqu'il est utilisé comme un nom, un chiffre ou un numéro). Ainsi, on a : « Un total de huit livres - Un paquet de onze kilos - Le un de cette rue – Une bouteille de un litre – Le huitième rang – Le onzième jour ». Une exception avec l'expression « le bouillon de onze heures » qui peut aussi s'écrire : « le bouillon d’onze heures ». L’article indéfini un peut être précédé d’une apostrophe.
« Elle le regardait d’un air inquiet ». - oui – « Des millions de oui »
- Devant les mots commençant par un y suivi d’une autre voyelle avec laquelle il forme le son ['j], comme dans yaourt, yacht, yoyo. « Le yaourt - Un port rempli de yachts - Une boîte pleine de yoyos »
Les voyelles a et e, de même que i pour ce qui est de la conjonction si suivie du pronom sujet il, étant les seules à pouvoir être élidées, il est à noter que :
- Le i de qui n’est jamais élidé. Il ne faut pas confondre que et qui notamment lorsqu’il s’agit d’utiliser une apostrophe. Comparez : « La photo qui illustre cette page » et « La page qu’illustre cette photo ».
- De même, le u de du n’est jamais élidé. L’article du - contraction de de le - ne peut être ni élidé, ni suivi d’un mot commençant par une voyelle ou un h muet. Avec un mot commençant par une voyelle ou un h muet, on doit utiliser de l’ comme dans l’exemple suivant : « l’équipage de l’avion » et non « d’avion ». Comparez avec : « l’équipage du navire ».
Dans certains cas, l’emploi de l’apostrophe est erroné bien qu’entré dans l’usage au début du XXe siècle par hypercorrection. Il n’y a aucune élision dans prud’homme (prud, anciennement prod, c’est-à-dire preux, + homme) ou grand’rue (grand, forme de féminin en ancien français écrite normalement grant, + rue). Aujourd’hui, dans ce cas, on écrirait plutôt prudhomme, grand rue ou grand-rue. En revanche, si grand’mère, a été employé jusqu’au début du XXe siècle, on n’est jamais allé jusqu’à écrire mère grand’ ou Rochefort’.
Autres usages
Si les usages autres que l’élision sont considérés comme fautifs, on observe cependant de façon anecdotique d’autres usages. Il subsiste de façon archaïque, avec la fonction d’un trait d’union, dans des termes comme grand’mère ou grand’chose en l’absence d’élision. La huitième édition (1932-1935) du Dictionnaire de l’Académie française entérine le remplacement de cette apostrophe par un trait d’union[20]. Grand’ était alors invariable et l’on écrivait par exemple « les grand’mères » et « les grands-pères ». Les milieux proches de l’ordre national de la Légion d’honneur semblent attachés contre l’Académie à la graphie « grand’croix »[21].
L’apostrophe simple ou double peut aussi être utilisée comme substitut du guillemet (la première est renversée ou une virgule renversée), notamment quand une citation ou un discours direct sont insérés dans une autre citation ; cet usage provient des guillemets anglais[22]. On la trouvait dans la typographie française XVIIe - fin XVIIIe siècle pour remplacer un accent aigu en la plaçant après un E majuscule pour accentuer des lettres capitales: E' est équivalent à É .
Autres langues et systèmes orthographiques
En anglais
L’apostrophe est communément utilisée pour indiquer les caractères omis en raison d’un amuïssement :
- dans des abréviations, comme gov’t pour government (« gouvernement ») ou ’70s pour 1970s (seventies) ;
- dans des contractions telles que can’t pour cannot (« ne pas pouvoir ») et it’s pour it is (« c’est ») ou it has (« cela a »).
- De façon exceptionnelle, on peut aussi trouver une combinaison des deux : bo’s’n’s pour boatswain’s.
L’utilisation la plus courante de l’apostrophe, cependant, est liée au génitif anglais (encore appelé cas possessif), qui se marque normalement par une désinence -s ajoutée au mot voulu. Ce suffixe est séparé du mot par l’apostrophe, qui joue donc un rôle de démarcation morphématique (comme dans d’autres langues) : Oliver’s army → « de Olivier + [l’]armée » = « l’armée d’Olivier », Elizabeth’s crown → « de Élisabeth + couronne » = « la couronne d’Élisabeth ». Dans les enseignes telles que McDonald’s (qui serait à traduire par « Chez McDonald ») un substantif est sous-entendu : McDonald’s shop = la « boutique de McDonald ».
Enfin, l’apostrophe est utilisée par certains écrivains dans une fonction similaire de séparation des morphèmes pour des pluriels d’abréviations ou de symboles dans lesquels n’ajouter que la désinence -s (homophone du -s de génitif) serait ambigu, comme dans mind your p’s and q’s plutôt que mind your ps and qs (« surveillez vos p et q », c’est-à-dire « comportez-vous correctement », expression idiomatique intraduisible telle quelle). Ce procédé n’est pas nécessaire quand il n’y a pas d’ambiguïté : CDs, videos et 1960s suffisent, CD’s, video’s et 1960’s n’ayant pas de justification liée à la lisibilité. De même, l’emploi systématique actuel de l’apostrophe pour des mots n’ayant normalement pas de pluriel (verbes, adverbes…) est souvent erroné : le titre du film Dating Do’s and Don’ts devrait être écrit Dating Dos and Don’ts.
Difficultés
Le bon placement d’une apostrophe, en anglais, peut significativement changer le sens d’un énoncé. On prendra particulièrement garde aux cas suivants.
Homophonies
L’apostrophe de it’s (« c’est » ou « cela a ») marque une contraction de it is ou bien it has. Le possessif (adjectif ou pronom) its (« son, sa », « le sien, la sienne », quand le possesseur est neutre) n’a pas d’apostrophe. On peut se souvenir qu’il n’y a pas d’apostrophe dans les pronoms possessifs his (masculin), hers (féminin) et its.
Who’s signifie « qui est » ou « qui a ». On ne le confondra pas avec le possessif de who, whose « dont » / « à qui » : the person whose responsibility it is is the member who’s oldest (littéralement « la personne dont c’est la responsabilité est le membre qui est le plus âgé »).
You’re signifie « vous [tu] êtes [es] », qu’on ne confondra pas avec le possessif your (« votre [ton/ta] »). « Your nuts » signifie « tes noix » alors que « you’re nuts » se traduit par « t’es noix », idiotisme familier pour « tu es fou ».
Disparition du -s de génitif après un autre -s
Quand un nom est mis au pluriel en -s, le génitif ne prend pas de -s supplémentaire mais l’apostrophe est conservée : lady’s hat, « le chapeau de dame » (singulier) mais ladies’ hats, « le(s) chapeau(x) des dames » (pluriel). Les pluriels irréguliers sans -s sont construits normalement au génitif : child’s hat, « le chapeau de l’enfant », children’s hats, « le(s) chapeau(x) des enfants ».
Un nom terminé au singulier par un -s peut ne pas recevoir un -s supplémentaire au génitif. Encore une fois, l’apostrophe est conservée : Jesus’ parables (« les paraboles de Jésus »). Cet usage est le plus courant aux États-Unis d’Amérique, surtout avec les noms anciens : Eros’ statue (« la statue d’Éros »), Herodotus’ book (« le livre d’Hérodote »). Des noms modernes se terminant par -es (prononcé avec /z/ et non /s/) suivent parfois cette règle : Charles’ car (« la voiture de Charles ») alors que la norme enseigne qu’il faudrait écrire Charles’s car. Par extension, on fait aussi de même avec des mots terminés par -x ou -z. (À l’oral, on prononce le ’s, par exemple « Jesus’ » se prononce souvent /dʒi:zəsəs/.)
Il existe des irrégularités, qu’on rencontre surtout dans les toponymes : si on trouve à Londres un St James’s Park (James est un singulier terminé par -s), il y a à Édimbourg une Princes Street, qu’il faudrait écrire avec une apostrophe puisque Princes est au pluriel ;
Greengrocers’ apostrophes
Des apostrophes mal placées, en particulier avec un « s » de pluriel, sont nommées Greengrocers’ apostrophes (ou, ironiquement, Greengrocers apostrophe’s), « apostrophes de l’épicier » (littéralement, du primeur), en raison des occurrences erronées censées être fréquentes sur les panonceaux écrits à la main qu’on peut trouver dans leur magasin, indiquant des potatoe’s (« pommes de terres ») ou des cabbage’s (« choux »).
En breton
En breton le trigramme « cʼh » note une consonne fricative vélaire voisée, [ɣ], ou sourde, [x], ou encore une consonne fricative glottale sourde, [h]. Exemple : François Falcʼhun. Autrefois, le digramme ʼf notait un son intermédiaire entre f et v. Ce digramme est toutefois encore employé dans l’orthographe dite universitaire, mais cette orthographe est de plus en plus minoritaire.
L’utilisation de la lettre modificative apostrophe (ʼ, U+02BC) est recommandée par l’Office public de la langue bretonne[23], mais l’usage de l’apostrophe dactylographique (U+0027) ou de l’apostrophe typographique (U+2019) reste courant.
Amuïssements autres que l’élision
L’amuïssement de certains phonèmes (apocope et aphérèse) se marque avec l’apostrophe en gaélique (où il existe des amuïssements obligatoires et facultatifs, comme en anglais). Par exemple, en gaélique écossais : is toil leam a bhith ag dannsadh → ’s [facultatif] toil leam a bhith a’ [obligatoire] dannsadh « j’aime danser »).
Séparation des morphèmes
L’apostrophe peut servir à séparer des morphèmes, surtout dans des mots sentis comme étrangers ou spécifiques. Ainsi, en néerlandais, elle peut être utilisée dans certains pluriels étrangers pour séparer le radical de la terminaison de pluriel irrégulière : foto’s, taxi’s. Le procédé se retrouve en turc : elle sert surtout dans les noms propres et joue là aussi un rôle séparateur (entre le radical et les suffixes). On trouvera donc souvent écrit İzmir’de, « à Izmir » au lieu de İzmirde. On a aussi vu que l’anglais fait parfois de même, dans des cas plus rares, cependant.
Séparation des syllabes dans la transcription
Dans certaines transcriptions, dont le pīnyīn (romanisation du mandarin) et plusieurs transcriptions du japonais (nippon-shiki, méthode Hepburn, par exemple), l’apostrophe permet de lever des ambiguïtés en séparant des syllabes qu’on pourrait sinon lire de plusieurs manières dans des mots polysyllabiques.
Par exemple, en pīnyīn changan est une graphie ambiguë : faut-il lire chang an ou chan gan ? L’ambiguïté disparaît une fois que l’on écrit chang’an, l’apostrophe indiquant la séparation virtuelle entre les deux syllabes chang et an. Dans les faits, changan doit se lire chan gan et c’est chang an qu’on distingue par l’apostrophe (on n’écrit pas chan’gan).
Pour le japonais, c’est avec la nasale moraïque qu’on peut trouver des ambiguïtés : dans cette langue, en effet, il existe une consonne comptant pour une more et ne pouvant se trouver qu’en fin de syllabe et s’opposant à une consonne nasale simple n’existant qu’en début de syllabe. Dans un mot polysyllabique, la coupure entre les syllabes n’est pas toujours évidente dans la transcription : ainsi kan’i (avec trois mores : ka+n+i) peut être différencié de kani (en deux mores : ka+ni) dès que l’on utilise l’apostrophe. Ce détail prend toute son importance quand on sait que l’orthographe en kanas change radicalement. Par exemple, kan’i s’écrit かんい tandis que kani s’écrit かに (hiragana).
Marque de palatalisation
Il est fréquent que l’apostrophe serve, soit dans une orthographe latine, soit dans les transcriptions et translittérations, à noter la présence d’une palatalisation. Elle joue là un rôle diacritique adscrit (l’apostrophe ne se place normalement pas sur ou sous une lettre ; c’est dans ce cas un autre type de diacritique, comme une virgule sous- ou suscrite).
Le cas du slovaque et du tchèque est notable : alors que dans ces langues la palatalisation est normalement indiquée par le háček, il est d’usage, pour les textes imprimés, de le remplacer par une apostrophe après les consonnes à hampe, soient t, d, l et la capitale L. Cet usage permet d’améliorer la lisibilité mais n’est pas obligatoire avec toutes les lettres ; ainsi, on trouve les couples suivants :
- Ť ~ ť [c] ;
- Ď ~ ď [ɟ] ;
- Ľ ~ ľ (seulement en slovaque) [ʎ].
Selon la police de caractères à utiliser pour afficher cette page, il est possible que le háček soit utilisé à la place de l’apostrophe, surtout pour L ~ l.
Pour Unicode, ces caractères sont dits « avec háček », quel que soit l’œil du glyphe. L’apostrophe, le cas échéant, n’est pas un caractère supplémentaire mais fait bien partie de la lettre. Il serait maladroit d’écrire dostʼ (ou, pire, dost') au lieu de dosť. Cette erreur est encore plus visible avec le Ľ slovaque : Ľ n’est pas identique à Lʼ ou L' (pour peu que votre navigateur affiche bien un L avec apostrophe adscrite). Le Ľ ne doit pas non plus être confondu avec le Ĺ, l long, qui existe également dans cette langue.
L’apostrophe est aussi utilisée pour marquer la palatalisation dans certaines transcriptions de mots russes. Dans l’alphabet cyrillique, c’est souvent un « signe mou » qui joue ce rôle. Ainsi, on pourra transcrire объя́ть par ob”ât’ « embrasser », où t’ transcrit le т palatalisé (indiqué par ь). Le signe dur (indiquant l’absence de palatalisation et la presence d’un phonème /j/ intercalaire) est rendu par un guillemet fermant courbe. En biélorusse et en ukrainien, l’apostrophe est utilisée dans l’orthographe cyrillique entre une consonne et une voyelle molle pour indiquer la présence d’un phonème /j/ intercalaire au lieu du signe dur du russe.
Coup de glotte
Dans diverses orthographes et transcriptions ou translittérations, l’apostrophe indique un coup de glotte ([ʔ]) : cheyenne ma’eno [maʔɪno̥], « tortue » (orthographe) ou amharique ስብአ säbʾä [sɜbʔɜ], « peuple » (transcription). L’apostrophe est dans ce cas une lettre à part entière. Il est notable qu’elle est aussi utilisée à cet effet en turc, langue dans laquelle le coup de glotte n’est cependant pas pertinent (et rarement prononcé) : tel’in [telʔin], « dénonciation ». Le turc utilise donc ce signe de deux manières différentes (séparation des morphèmes et coup de glotte).
L’utilisation de l’apostrophe pour marquer le coup de glotte est aussi très répandue dans la transcription des langues sémitiques. Le caractère attendu dans une bonne composition typographique pour ces dernières langues, cependant, est un demi-anneau à droite, ʾ (voir plus haut). À l’inverse des conventions sémitiques, c’est une apostrophe culbutée, dite ‘okina, qui note le coup de glotte en hawaïen.
Glottalisation
En alphabet phonétique international ainsi que dans l’orthographe latine de certaines langues d’Afrique, la lettre apostrophe placée après une consonne sourde indique qu’il s’agit d’une éjective. Dans certaines langues d’Afrique (mais pas en API dans les cas les plus courants, où l’on utilise des lettres à crosse : /ɓ, ɗ/), elle peut aussi précéder une consonne sonore pour en indiquer le caractère injectif ; inversement, la graphie consonne sourde + lettre apostrophe est assez rare dans les orthographes africaines, des graphies avec un caractère à crosse étant préférées (ƙ, ƭ). Il faut donc là considérer la lettre apostrophe comme une consonne (notant en dernière analyse un coup de glotte) faisant partie d’un digramme.
Ainsi, en API [pʼ] note une éjective bilabiale et on trouve dans les orthographes de quelques langues d’Afrique les combinaisons suivantes (le nom du pays indiqué entre parenthèses n’est pas tant celui où la langue est parlée ─ certaines étant étendues sur plusieurs nations ─ que celle où l’orthographe indiquée est suivie) :
- k’ /k’/ en duruma (Kenya) ;
- t’ /t’/ en sérère (Sénégal) ;
- ’b /ɓ/ et ’d /ɗ/ en lélé (Tchad) et gbaya (Centrafrique) ;
- ’w /ˀw/ en daba (Cameroun) ;
- ’dj /ɗʒ/ en jur modo (Soudan) ;
- ’y /ˀj/ en peul et haoussa (Nigeria ; au Niger, c’est la graphie ƴ qui est préférée).
Remarque : le symbole de glottalisation simple, [ˀ], n’est pas non plus une apostrophe.
Dans certains cas, l’apostrophe ne joue qu’un rôle diacritique sans lien avec une éventuelle glottalisation : ng’ en souahéli (Kenya) note /ŋ/ tandis que ng note ŋg. Seul ng’ est un digramme, ng étant une suite de consonnes.
On remarque que, dans ces deux derniers emplois, coup de glotte et glottalisation, l’utilisation de l’apostrophe est graphiquement lié (une consonne éjective pouvant être vue comme une consonne suivie d’un coup de glotte ou précédée d’un coup de glotte quand c’est une injective). Les graphies sont, dans les orthographes africaines, parfois plus analytiques qu’en API (k’ = k + ’ = /k/ + /ʔ/ = /k’/ et inversement ’b = ’ + b = /ʔ/ + /b/ = /ɓ/).
Aspiration
Dans la transcription traditionnelle de l’arménien, c’est le demi-anneau gauche qui note l’aspiration d’une consonne, souvent remplacé pour des raisons de commodité typographique par une apostrophe culbutée courbe, symbole qui s’utilise exclusivement pour la même fonction dans la transcription des langues chinoises. Ainsi, les digrammes kʿ ou k‘ se liront [kʰ].
Tonalité
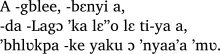
Dans la transcription de certaines langues tonales africaines (comme l’angas, le bété, le dan, le godié, le grebo, le karaboro, le kroumen tépo, le muan, le nyabwa, le wan, le wobé, ou le yaouré), l’apostrophe est utilisée comme diacritique pour indiquer un ton spécifique. Le caractère Unicode ʼ (U+02BC lettre modificative apostrophe) est préféré aux autres apostrophes ' (U+0027) ou ’ (U+2019).
En grebo, nyabwa, wobé et yaouré, la double apostrophe ˮ (U+02EE lettre modificative double apostrophe) est utilisée pour indiquer le ton haut et le différencier du ton mi-haut, indiqué avec la simple apostrophe.
Domaines
Mathématiques et physique
L’apostrophe droite est souvent utilisée pour représenter le signe mathématique prime, le symbole des mesures en pieds (en concurrence avec ft) et des minutes d’arc : A' (ou A′ idéalement) se lit donc « A prime » et 12' (ou 12′ idéalement) vaut « 12 pieds » ou « 12 minutes d’arc ». Il convient cependant de ne pas l’utiliser pour les minutes temporelles (dont l’abréviation est min). Unicode prévoit cependant un caractère distinct (voir plus bas dans le tableau : #Codage du caractère apostrophe).
Certains logiciels de calcul scientifiques savent interpréter l’apostrophe droite comme un prime. Ainsi Mathematica (mais pas Maple) lit f' comme la dérivée de la fonction f (cela ne fonctionne que si f est une fonction d’une seule variable).
Informatique
Codage du caractère apostrophe
| nom | glyphe | Unicode | Version Unicode | codePage 1252 | MacRoman | entité HTML |
|---|---|---|---|---|---|---|
| Apostrophe | Oo'Oo | U+0027 = 39 | Unicode 1.1.0 | 0x27 = 39 | 0x27 = 39 | |
| Guillemet-apostrophe | Oo’Oo | U+2019 = 8217 | Unicode 1.1.0 | 0x92 = 146 | 0xD5 = 213 | ’ |
| Lettre modificative apostrophe | OoʼOo | U+02BC = 700 | Unicode 1.1.0 | |||
| Lettre modificative virgule culbutée | OoʻOo | U+02BB = 699 | Unicode 1.1.0 | |||
| Lettre modificative virgule réfléchie | OoʽOo | U+02BD = 701 | Unicode 1.1.0 | |||
| Lettre modificative demi-anneau à droite | OoʾOo | U+02BE = 702 | Unicode 1.1.0 | |||
| Lettre modificative demi-anneau à gauche | OoʿOo | U+02BF = 703 | Unicode 1.1.0 | |||
| Lettre modificative ligne verticale | OoˈOo | U+02C8 = 712 | Unicode 1.1.0 | |||
| Diacritique virgule en chef | Ooo̓Oo | U+0313 = 787 | Unicode 1.1.0 | |||
| Diacritique virgule en chef à droite | Ooo̕Oo | U+0315 = 789 | Unicode 1.1.0 | |||
| Apostrophe arménienne | Oo՚Oo | U+055A = 1370 | Unicode 1.1.0 | |||
| Guillemet-apostrophe culbuté | Oo‘Oo | U+2018 = 8216 | Unicode 1.1.0 | 0x91 = 145 | 0xD4 = 212 | ‘ |
| Guillemet-virgule inférieur | Oo‚Oo | U+201A = 8220 | Unicode 1.1.0 | 0x82 = 130 | 0xE2 = 226 | ‚ |
| Guillemet-virgule supérieur culbuté | Oo‛Oo | U+201B = 8221 | Unicode 1.1.0 | |||
| Virgule | Oo, Oo | U+002C = 44 | Unicode 1.1.0 | 0x2C = 44 | 0x2C = 44 | |
| Accent grave (avec chasse) | Oo`Oo | U+0060 = 96 | Unicode 1.1.0 | 0x60 = 96 | 0x60 = 96 | |
| Accent aigu (avec chasse) | Oo´Oo | U+00B4 = 180 | Unicode 1.1.0 | 0xB4 = 180 | 0xAB = 171 | ´ |
| Prime | Oo′Oo | U+2032 = 8242 | Unicode 1.1.0 | ′ | ||
| Lettre modificative prime | OoʹOo | U+02B9 = 697 | Unicode 1.1.0 | |||
| Prime réféchi | Oo‵Oo | U+2035 = 8245 | Unicode 1.1.0 | |||
| Letter latin majuscule saltillo | OoꞋOo | U+A78B = 42891 | Unicode 5.1.0 | |||
| Letter latin minuscule saltillo | OoꞌOo | U+A78C = 42892 | Unicode 5.1.0 |
Note : Les codes Unicode sont identiques aux codes ASCII jusqu’à 127, et identiques aux codes ISO 8859-1 jusqu'à 255.
Unicode recommande l’utilisation du guillemet-apostrophe (U+2019) pour représenter l’apostrophe[8],[9].
Ambiguïtés
Le caractère apostrophe ‹ ' › U+0027, codé dans le standard ASCII comme apostrophe, guillemet anglais fermant, accent aigu, et repris comme tel dans Unicode est ambigu. Des caractères supplémentaires ont été codés pour lever certaines ambiguïtés car celui-ci peut être courbe, droit ou oblique. Il est principalement utilisé pour représenter l’apostrophe mais il peut être utilisé pour représenter plusieurs signes ou lettres lorsque ceux-ci ne sont pas disponibles :
- ‹ ’ ›, le caractère guillemet-apostrophe, dite apostrophe typographique, recommandée pour le signe de ponctuation apostrophe
- par exemple « l'enfant » au lieu de « l’enfant ».
- ‹ ʼ ›, la lettre apostrophe, lettre de certains alphabets ou symbole phonétique
- par exemple « ma'eno » au lieu de « maʼeno », ou [p'] au lieu de [pʼ].
- ‹ ʽ ›, la lettre virgule culbutée ou okina, lettre de certains alphabets
- par exemple « 'okina » au lieu de « ʻokina » ;
- ‹ ‘ ’ ›, le guillemet simple anglais de gauche ou de droite
- par exemple « 'word' » au lieu de « ‘word’ »
- ‹ ˈ ›, la ligne verticale haute indiquant l’accent tonique principale dans l’Alphabet phonétique international ;
- par exemple ['fa.to] au lieu de ['fa.to] ;
- ‹ Ꞌ ꞌ ›, le saltillo majuscule ou minuscule, lettre de certains alphabets
- par exemple « ME̱E̱'PHA̱A̱ » au lieu de « ME̱E̱ꞋPHA̱A̱ », ou « me̱e̱'pha̱a̱ » au lieu de « me̱e̱ꞌpha̱a̱ » ;
- ‹ ′ ›, le prime, signe de ponctuation aussi utilisé pour la minute d’arc ou la minute de temps ;
- par exemple « f'(x) » au lieu de « f′(x) », ou « 40° 20'50" » au lieu de « 40° 20′50″ »
- ‹ ʹ ›, le prime, lettre de certains systèmes de translittération
- par exemple ять retranscrit par yat' au lieu de yatʹ
- ‹ ´ ›, l’accent aigu avec chasse ;
- ‹ ´ ›, la lettre accent aigu, indiquant un ton ;
- ‹ ΄ ›, le tonos grec
- par exemple « Α' της » au lieu de « Α΄ της » ;
- ‹ ʿ ›, le demi-anneau à gauche, transcrivant le ʿayn arabe
- par exemple ﻋﻴﻦ retranscrit par « 'ayn » au lieu de « ʿayn ».
Usage en langage informatique
En raison de leur contemporanéité relative, les apostrophes ASCII sont utilisées dans de nombreux langages informatiques pour délimiter les chaînes de caractères.
Dans certains langages, les apostrophes et les guillemets sont équivalents. Ainsi, on peut entourer sans ambiguïté de guillemets une chaîne contenant des apostrophes, et inversement, sans devoir utiliser un caractère d’échappement. C’est par exemple le cas des langages respectant la syntaxe XML, comme XHTML :
<img src='cui cui.jpeg' alt="l'oiseau"/>
Certains langages font la distinction entre un simple caractère et une chaîne de caractères. Dans ce cas, les simples caractères sont entourés d’apostrophes et les chaînes de guillemets. Exemple en langage C qui affiche « ABCD » :
putchar('A');
puts("BCD");
Des langages de script utilisent les apostrophes pour entourer les chaînes, les guillemets pour entourer les chaînes qui subissent une interpolation des variables, et l’accent grave pour entourer les chaînes qui sont remplacées par la sortie de la commande informatique qu’elles contiennent. Par exemple, le script shell Unix suivant :
A=`date` # A vaut le résultat de la commande date
echo 'la date : $A'
echo "la date : $A"
affiche :
la date : $A la date : ven déc 31 19:39:43 CET 2004
Les apostrophes sont utilisées pour marquer l’emphase typographique dans la syntaxe wiki du logiciel MediaWiki. Ainsi, entourer un mot de deux apostrophes le met en italique, de trois le fait représenter en gras : ''italique'' → italique, '''gras''' → gras.
| Types de guillemets | Langages |
|---|---|
| apostrophes et guillemets équivalents | SGML, XML, JavaScript |
| apostrophes pour les caractères, guillemets pour les chaînes | C, C++, OCaml, Java |
| apostrophes pour les chaînes, guillemets pour interpoler les variables | PHP |
| apostrophes pour les chaînes, guillemets pour interpoler les variables, accent grave pour les commandes | Shell Unix, Perl |
Notes et références
- ↑ Entrée Apostrophe, première édition du Dictionnaire de l'Académie française, 1694, lire en ligne
- 1 2 Entrée Apostrophe, Orthotypographie, par Jean-Pierre Lacroux
- ↑ Yann Haralambous, Fontes et codages, 2004, p. 29.
- ↑ aussi appelée de façon plus imagée « chiure de mouche » (dans l’argot des typographes) ou impostrophe (néologisme et belgicisme, mot-valise composé de « imposteur » et « apostrophe »)
- ↑ Aurel Ramat, Le Ramat de la typographie : édition 2008, 9e édition, 2008, 224 pages (ISBN 9782922366044), page 170 : « Pour changer l’apostrophe dactylographique par l’apostrophe typographique on remplace Ansi Alt 039 par Ansi Alt 0146 dans {Outil, Correction automatique}. »
- ↑ (fr) [PDF] Les claviers disposent de l’apostrophe dactylographique ( ' ), mais il est préférable d’utiliser l’apostrophe typographique ( ’ ), Chronique de la société royale Le Vieux-Liège, Fabrice Muller, 2005.
- ↑ André 2008
- 1 2 (fr) [PDF] Unicode Intervalle : 0000—007F
- 1 2 (fr) [PDF] Intervalle : 2000—206F.
- ↑ (fr) Unicode 5.0 en pratique, chapitre 7 « Ponctuation », Patrick Andries.
- ↑ (en) ANSl X3.4-1986, Coded Character Set - 7-bit American National Standard Code for Information Interchange (ASCII), 1986, p. 12
- ↑ (en) [PDF] Unicode Standard 6.1.0, p. 193.
- 1 2 3 4 5 6 7 André 2008
- ↑ Weil et Benloew 1815, p. 316
- ↑ André 2008 indique que la grammaire de Alberti est connue en 1494, d’autres sources donnent une année autour de 1450.
- ↑ Guillemain 2011
- ↑ Mat Pires, « Leçons de Gram’hair : fonctions de l’apostrophe en onomastique commerciale », langage et société, no 91, , p. 60
- ↑ Jacques André, « Funeste destinée : L’apostrophe détournée », Graphê, no 39, , p. 7 (ISSN 1168-3104, lire en ligne)
- 1 2 3 Grevisse 1986 § 44, § 45 et § 106
- ↑ Grevisse 2011 § 543
- ↑ Sur la persistance de la graphie « grand’croix », voir le titre de l’ouvrage : Michel et Béatrice Wattel, Les Grand’Croix de la Légion d’honneur : De 1805 à nos jours, titulaires français et étrangers, Archives et Culture, 2009, 701 pages (ISBN 9782350771359).
- ↑ Grevisse 1986 § 133
- ↑ Dans le Common Locale Data Repository (CLDR), CLDR.
Annexes
Bibliographie
- Jacques André, « Funeste destinée : L’apostrophe détournée », Graphê, no 39, , p. 2–11 (ISSN 1168-3104, lire en ligne)
- Maurice Grevisse et André Goose, Le Bon Usage, de Boeck Duculot, , 12e éd.
- Maurice Grevisse et André Goose, Le Bon Usage, de Boeck Duculot, , 15e éd. (ISBN 978-2-801116425)
- Maurice Grevisse et André Goose, « Le Bon Usage », de Boeck, (consulté le 18 août 2012)
- Jean Guillemain, « Le livre à la Renaissance », L’aventure du livre, Bibliothèque nationale de France (BnF), (consulté le 17 août 2012)
- Mat Pires, « Leçons de Gram’hair : fonctions de l’apostrophe en onomastique commerciale », Langage et société, no 91, , p. 59-86 (ISSN 0181-4095 et 2101-0382, lire en ligne)
- Henri Weil et Louis Benloew, Théorie générale de l’accentuation latine, Berlin : Ferdinand Dümmler et Ce, Paris : Librairie A. Durand,
Articles connexes
- Ponctuation
- Typographie
- Diacritiques de l’alphabet latin
- Okina
Lien externe
- Entrée « Apostrophe » dans l’œuvre en ligne de Jean-Pierre Lacroux (1947-2002) ; consulté le 17 août 2012.
 Portail de l’écriture
Portail de l’écriture