
Margen de error
Antecedentes de las escuelas de Wikipedia
Esta selección wikipedia ha sido elegido por los voluntarios que ayudan Infantil SOS de Wikipedia para esta Selección Wikipedia para las escuelas. SOS Children trabaja en 45 países africanos; puede ayudar a un niño en África ?

El margen de error es una estadística que expresa la cantidad de azar error de muestreo en un Los resultados de la encuesta. Cuanto mayor sea el margen de error, menos confianza que uno debe tener esa reportados resultados de la encuesta se encuentran cerca de las cifras "reales"; es decir, las cifras para el conjunto población.
Explicación
El margen de error se define generalmente como la radio de una intervalo de confianza para un particular, estadística de una encuesta. Un ejemplo es el porcentaje de personas que prefieren productos A versus el producto B. Cuando se informa de un solo margen global de error de la encuesta, que se refiere al margen de error máximo de todos los reportados porcentajes utilizando la muestra total de la encuesta. Si la estadística es un porcentaje, este margen máximo de error se puede calcular como el radio del intervalo de confianza para un porcentaje reportado de 50%.
El margen de error ha sido descrita como una cantidad "absoluta", igual a un radio de intervalo de confianza para la estadística. Por ejemplo, si el valor real es de 50 puntos porcentuales, y la estadística tiene un radio intervalo de confianza de 5 puntos porcentuales, entonces decimos que el margen de error es de 5 puntos porcentuales. Como otro ejemplo, si el valor real es de 50 personas, y la estadística tiene un radio intervalo de confianza de 5 personas, entonces podríamos decir que el margen de error es de 5 personas.
En algunos casos, el margen de error no se expresa como una cantidad "absoluta"; sino que más bien se expresa como una cantidad "relativo". Por ejemplo, supongamos que el valor real es de 50 personas, y la estadística tiene un radio intervalo de confianza de 5 personas. Si utilizamos la definición "absoluta", el margen de error sería de 5 personas. Si utilizamos la definición "relativa", a continuación expresamos este margen absoluto de error como un porcentaje del valor real. Así que en este caso, el margen de error es de absoluta 5 personas, pero el "porcentaje relativo" margen de error es del 10% (debido a 5 personas son diez por ciento de 50 personas). A menudo, sin embargo, no se hace explícita la distinción, sin embargo, por lo general se desprende del contexto.
Al igual que los intervalos de confianza, el margen de error se puede definir para cualquier nivel de confianza deseado, pero por lo general se elige un nivel de 90%, 95% o 99% (típicamente 95%). Este nivel es la probabilidad de que un margen de error en torno al porcentaje reportado incluiría el "verdadero" porcentaje. Junto con el nivel de confianza, el diseño de la muestra para una encuesta, y en particular su tamaño de la muestra, determina la magnitud del margen de error. Un tamaño de la muestra más grande produce un menor margen de error, todo lo demás queda igual.
Si se utilizan los intervalos de confianza exactos, entonces el margen de error tiene en cuenta tanto el error de muestreo y errores ajenos al muestreo. Si se utiliza un intervalo de confianza aproximada (por ejemplo, suponiendo que la distribución es normal y luego modelar el intervalo de confianza en consecuencia), a continuación, el margen de error sólo puede tomar al azar error de muestreo en cuenta. No representa otras posibles fuentes de error o sesgo, como una muestra de diseño no representativa, mal preguntas redactadas, la gente miente o negarse a responder, la exclusión de las personas que no pudieron ser contactados o miscounts y errores de cálculo.
Concepto
Ejemplo Correr
Un ejemplo de ejecución de la 2004 campaña presidencial de Estados Unidos se utilizará para ilustrar los conceptos a lo largo de este artículo. De acuerdo con una 2 de octubre de 2004 por la encuesta Newsweek, el 47% de los votantes registrados votaría por John Kerry / John Edwards, si las elecciones se celebraran en ese día, el 45% votaría a favor de George W. Bush / Dick Cheney, y el 2% votaría por Ralph Nader / Peter Camejo. La tamaño de la muestra fue de 1,013. A menos que se indique lo contrario, el resto de este artículo utiliza un 95% de confianza.
Concepto básico
Las encuestas típicamente implican tomar una muestra de una población determinada. En el caso de la encuesta de Newsweek, la población de interés es la población de personas que van a votar. Debido a que es poco práctico para sondear todos los que van a votar, los encuestadores toman muestras más pequeñas que están destinados a ser representativos; eso es un muestra aleatoria de la población. Es posible que los encuestadores muestrean 1.013 votantes que suceden a votar por Bush cuando en realidad la población se divide en partes iguales entre Bush y Kerry, pero esto es muy poco probable (p = 2 -1013 ≈ 1,13923782 × 10 -305), dado que la muestra es azar.
La teoría del muestreo proporciona métodos para calcular la probabilidad de que los resultados de las encuestas difieren de la realidad por más de una cierta cantidad, simplemente debido a la casualidad; por ejemplo, que la encuesta reporta 47% para Kerry pero su apoyo es realmente tan alto como 50%, o es realmente un precio tan bajo como 44%. Esta teoría y algunos Supuestos bayesianos sugieren que el "verdadero" porcentaje será probablemente bastante cerca de 47%. Cuanta más gente que se muestrean, los encuestadores más confianza puede ser que el "verdadero" porcentaje es cercano al porcentaje observado. El margen de error es una medida de lo cerca que los resultados son susceptibles de ser.
Sin embargo, el margen de error sólo representa el error de muestreo al azar, por lo que es ciego a errores sistemáticos que pueden ser introducidos por la falta de respuesta o por la interacción entre la encuesta y los sujetos de la memoria, la motivación, la comunicación y el conocimiento.
Los cálculos suponiendo muestreo aleatorio
En esta sección se discutirá brevemente el error estándar de un porcentaje, la correspondiente intervalo de confianza, y conectar estos dos conceptos para el margen de error. Para simplificar, los cálculos siguientes asumen que la encuesta se basa en una muestra aleatoria simple de una población grande.
El error estándar de una proporción o porcentaje reportado p mide su exactitud, y es la desviación estándar estimada de ese porcentaje. Se puede estimarse a partir de sólo p y el tamaño de la muestra, n, si n es pequeño en relación al tamaño de la población, utilizando la siguiente fórmula:
- Error estándar =
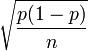
Cuando la muestra no es una muestra aleatoria simple de una población grande, el error estándar y el intervalo de confianza debe ser estimado mediante cálculos más avanzados. En la mayoría de los casos, el intervalo de confianza verdadera es aproximada suponiendo que la distribución es normal, y inputing el intervalo. Para distribuciones normales, las radios intervalo de confianza son proporcionales al error estándar. Por lo general, se desconoce la verdadera error estándar, por lo que el error estándar de la estimación se calcula a partir de los datos de la muestra.
Tenga en cuenta que no hay necesariamente una conexión estricta entre el intervalo de confianza verdadera, y el error estándar cierto. El intervalo de p-por ciento de confianza verdadera es el intervalo [a, b] que contiene p por ciento de la distribución, y donde (100-p) / 2 por ciento de la distribución se encuentra por debajo de un, y (100-p) / 2 por ciento de la distribución se encuentra por encima b. El error estándar verdadero de la estadística es la raíz cuadrada de la varianza verdadera muestra de la estadística. Estos dos pueden no estar directamente relacionado, aunque, en general, para las grandes distribuciones que se parecen a las curvas normales, existe una relación directa.
En la encuesta de Newsweek, el nivel de Kerry de apoyo p = 0,47 yn = 1.013. El error estándar (0.016 ó 1,6%) ayuda a dar un sentido de la exactitud de porcentaje estimado de Kerry (47%). La Interpretación bayesiana del error estándar es que, aunque no sabemos el "verdadero" porcentaje, es altamente probable que se encuentra dentro de los dos errores estándar del porcentaje estimado (47%). El error estándar se puede utilizar para crear un intervalo de confianza dentro de la cual el "verdadero" porcentaje debe ser a un cierto nivel de confianza.
El porcentaje estimado más o menos su margen de error es de un intervalo de confianza para el porcentaje. En otras palabras, el margen de error es de la mitad de la anchura del intervalo de confianza. Se puede calcular como un múltiplo del error estándar, con el factor dependiendo del nivel de confianza deseado; un margen de un error estándar da un intervalo de confianza del 68%, mientras que la estimación más o menos 1,96 errores estándar es un intervalo de confianza del 95%, y un intervalo de confianza del 99% corre 2,58 errores estándar a cada lado de la estimación.
Definición
El margen de error para una estadística particular de interés se define generalmente como el radio (o la mitad de la anchura) del intervalo de confianza para esa estadística. El término también puede usarse para significar un error de muestreo en general. En informes de prensa sobre resultados de la encuesta, el término se refiere a la margen máximo de error para cualquier porcentaje de esa encuesta.
Margen máximo de error
El margen de error máximo para cualquier porcentaje es el radio del intervalo de confianza cuando p = 50%. Como tal, se puede calcular directamente a partir del número de los encuestados. Para la confianza del 95%, asumiendo un muestra aleatoria simple de una población grande:
- (Máximo) Margen de error (95%) = 1,96 ×
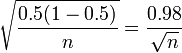
Este cálculo da un margen de error de 3% para la encuesta de Newsweek, que reportó un margen de error de 4%. La diferencia se debe probablemente a las funciones de ponderación o complejas del diseño de muestreo que requieren cálculos alternativos para el error estándar. También es posible que Newsweek han redondeado de forma conservadora para evitar exagerar la confianza de sus resultados.
Diferentes niveles de confianza
Para muestra aleatoria simple de una población grande, el margen máximo de error es un simple re-expresión del tamaño de la muestra n. Los numeradores de estas ecuaciones se han redondeado con dos decimales.
- Margen de error en confianza del 99%
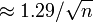
- El margen de error en la confianza del 95%
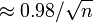
- Margen de error en confianza del 90%
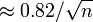
Si un artículo acerca de una encuesta no informa el margen de error, pero sí afirma que se utilizó una muestra aleatoria simple de un cierto tamaño, el margen de error puede ser calculado para un grado deseado de confianza mediante una de las fórmulas anteriores. Además, si se da el margen de 95% de error, se puede encontrar el margen de 99% de error mediante el aumento del margen comunicado de error en un 30%.
Márgenes máximos y específicos de error
Mientras que el margen de error normalmente se informó en los medios de comunicación es una figura-poll amplia que refleja la variación máxima de muestreo de cualquier porcentaje basado en todos los encuestados de esa encuesta, el término margen de error también se refiere a la radio del intervalo de confianza para un particular, estadística.
El margen de error de un porcentaje determinado individuo suele ser menor que el margen de error máximo de cotización de la encuesta. Este máximo sólo se aplica cuando el porcentaje observado es 50%, y el margen de error se reduce como el porcentaje se aproxima a los extremos de 0% o 100%.
En otras palabras, el margen máximo de error es el radio de un intervalo de confianza del 95% para un porcentaje reportado de 50%. Si p se aleja del 50%, el intervalo de confianza para p será más corto. Por lo tanto, el margen máximo de error representa un límite superior a la incertidumbre; uno es al menos un 95% seguro de que el "verdadero" porcentaje está dentro del margen de error máximo de un porcentaje reportado para cualquier porcentaje reportado.
Efecto del tamaño de la población
Las fórmulas anteriores para el margen de error asumen que hay una infinitamente grande población y por lo tanto no dependen del tamaño de la población de interés. De acuerdo con la teoría de muestreo , esta suposición es razonable cuando el fracción de muestreo es pequeño. El margen de error para un método de muestreo particular, es esencialmente el mismo independientemente de si la población de interés es el tamaño de una escuela, ciudad, estado o país, siempre y cuando la fracción de muestreo es inferior a 10%.
En los casos en que la fracción de muestreo es superior al 10%, los analistas pueden ajustar el margen de error con "corrección finita población" (FPC) para dar cuenta de la precisión añadido adquirido mediante el muestreo de cerca un porcentaje mayor de la población. FPC se puede calcular utilizando la fórmula:
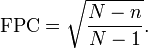
{kind=link}
Para el ajuste de una fracción de muestreo grande, la FPC en cuenta en el cálculo del margen de error, el cual tiene el efecto de reducir el margen de error. Se sostiene que el FPC se aproxima a cero como el tamaño de la muestra (n) se aproxima al tamaño de la población (N), que tiene el efecto de eliminar el margen de error completo. Esto tiene sentido intuitivo porque cuando N = n, la muestra se convierte en un censo y un error de muestreo se convierte en irrelevante.
Los analistas deben ser conscientes de que la muestra permanezca verdaderamente aleatoria como la fracción de muestreo crece, no sea que se introducirá sesgo de muestreo.
Otras estadísticas
Los intervalos de confianza se pueden calcular, y así pueden los márgenes de error, por una serie de estadísticas que incluyen porcentajes específicos, las diferencias entre los porcentajes, promedios, medianas y totales.
El margen de error para la diferencia entre dos porcentajes es mayor que los márgenes de error para cada uno de estos porcentajes, y puede incluso ser mayor que el margen de error máximo para cualquier porcentaje individual de la encuesta.
La comparación de los porcentajes
En un sistema de votación pluralidad, es importante saber quién está por delante. Los términos "empate técnico" y "empate técnico" se utilizan a veces para describir porcentajes reportados que difieren en menos de un margen de error, pero estos términos pueden ser engañosas. Por un lado, el margen de error calculado en general es aplicable a un porcentaje individual y no la diferencia entre los porcentajes, por lo que la diferencia entre dos estimaciones porcentuales puede no ser estadísticamente significativa incluso cuando difieren en más de la margen comunicado de error. Los resultados de la encuesta también a menudo proporcionan información fuerte, incluso cuando no hay una diferencia estadísticamente significativa.
Al comparar los porcentajes, en consecuencia puede ser útil considerar la probabilidad de que uno porcentaje es mayor que otro. En situaciones sencillas, esta probabilidad se puede derivar con 1) el cálculo del error estándar introducido antes, 2) la fórmula para la varianza de la diferencia de dos variables aleatorias , y 3) la suposición de que si alguien no elige Kerry elegirán Bush , y viceversa; están perfectamente negativamente correlacionados . Esto puede no ser una hipótesis defendible cuando existen más de dos posibles respuestas de los sondeos. Para diseños de encuestas más complejas, se deben utilizar diferentes fórmulas para calcular el error estándar de la diferencia.
El error estándar de la diferencia de porcentajes p para Kerry y q para Bush, en el supuesto de que están perfectamente correlacionados negativamente, del siguiente modo:
- El error estándar de la diferencia =
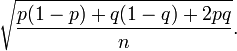
Dada la diferencia de porcentaje observado p - q (2% o 0,02) y el error estándar de la diferencia calculada anteriormente (0,03), cualquier calculadora estadística puede ser usada para calcular la probabilidad de que una muestra de una distribución normal con media 0,02 y estándar desviación 0,03 es mayor que 0.
La aplicación de estos cálculos a los resultados de ejemplo Newsweek en un 75% de probabilidad de que Kerry era "verdaderamente" líder.