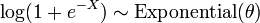Distribución exponencial
Antecedentes de las escuelas de Wikipedia
SOS Children, una organización benéfica educación , organizó esta selección. Con Infantil SOS se puede elegir a apadrinar a los niños en más de cien países
La función de densidad de probabilidad 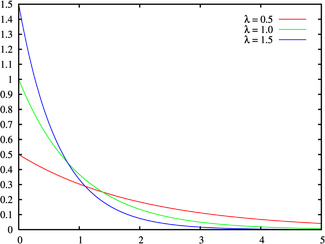 | |
Función de distribución acumulativa 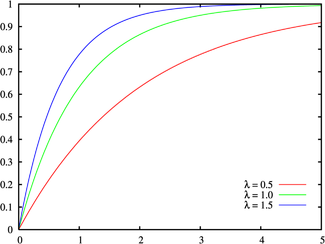 | |
| Parámetros | 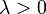 tasa o escala inversa ( verdadero ) tasa o escala inversa ( verdadero ) |
|---|---|
| Apoyo | 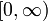 |
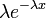 | |
| CDF | 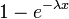 |
| Significar |  |
| Mediana | 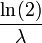 |
| Modo | 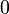 |
| Desacuerdo | 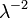 |
| Oblicuidad | 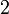 |
| Ex. curtosis | 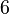 |
| Entropía | 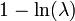 |
| MGF | 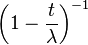 |
| CF | 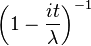 |
En teoría de la probabilidad y la estadística , las distribuciones exponenciales son una clase de continuas distribuciones de probabilidad . Una distribución exponencial surge naturalmente cuando se modela el tiempo entre eventos independientes que suceden a una velocidad media constante.
Caracterización
La función de densidad de probabilidad
La función de densidad de probabilidad (pdf) de una distribución exponencial tiene la forma

donde λ> 0 es un parámetro de la distribución, a menudo llamado el parámetro de velocidad. La distribución se apoya en el intervalo [0, ∞). Si una variable aleatoria X tiene esta distribución, escribimos X ~ Exponencial (λ).
Función de distribución acumulativa
La función de distribución acumulada está dada por

Parametrización alternativo
Una parametrización alternativa comúnmente utilizado es definir la función de densidad de probabilidad (pdf) de una distribución exponencial como

donde β> 0 es un parámetro de escala de la distribución y es la recíproco de la tasa parámetro, λ, se ha definido anteriormente. En esta especificación, β es un parámetro de la supervivencia en el sentido de que si una variable aleatoria X es la duración de tiempo que un sistema biológico o mecánico dado M arregla para sobrevivir y X ~ Exponencial (β), entonces ![\ Mathbb {E} [X] = \ beta](../../images/77/7760.png) . Es decir, la duración prevista de la supervivencia de M es β unidades de tiempo.
. Es decir, la duración prevista de la supervivencia de M es β unidades de tiempo.
Esta especificación alternativa a veces es más conveniente que la dada anteriormente, y algunos autores lo utilizará como una definición estándar. No asumiremos esta especificación alternativa. Desafortunadamente esto da lugar a una ambigüedad de notación. En general, el lector debe comprobar cuál de estas dos especificaciones se utiliza si un autor escribe "X ~ Exponencial (λ)", ya que o bien la notación en el anterior (usando λ) o la notación en esta sección (aquí, utilizando β para evitar la confusión) podría ser prevista.
Ocurrencia y aplicaciones
La distribución exponencial se produce naturalmente cuando se describen las longitudes de los tiempos entre llegadas en un homogénea Procesos de Poisson.
La distribución exponencial puede ser visto como una contraparte continua de la distribución geométrica, que describe el número de Ensayos de Bernoulli necesarias para un proceso discreto cambien de estado. En contraste, la distribución exponencial describe el tiempo para un proceso continuo de cambio de estado.
En los escenarios del mundo real, el supuesto de una tasa constante (o probabilidad por unidad de tiempo) es rara vez satisfecho. Por ejemplo, la tasa de llamadas telefónicas entrantes difiere de acuerdo con la hora del día. Pero si nos centramos en un intervalo de tiempo durante el cual la tasa es más o menos constante, por ejemplo, de 2 a 4 pm durante los días de trabajo, la distribución exponencial se puede utilizar como un buen modelo aproximado para el tiempo hasta la siguiente llamada telefónica llega. Advertencias similares se aplican a los siguientes ejemplos que producen variables de aproximadamente distribuidos de manera exponencial:
- el tiempo hasta que una partícula radiactiva decae, o el tiempo entre pitidos de una contador Geiger;
- el tiempo que toma antes de su próxima llamada telefónica
- el tiempo hasta que por defecto (en el pago a los tenedores de deuda de la compañía) en forma reducida de modelos de riesgo de crédito
Las variables exponenciales también se pueden utilizar para modelar situaciones donde se producen ciertos eventos con una probabilidad constante por unidad de distancia:
- la distancia entre mutaciones en un ADN hebra;
- la distancia entre roadkill en una calle determinada;
En la teoría de colas, los tiempos entre llegadas (es decir, los tiempos entre los clientes que entran en el sistema) a menudo se modelan como variables distribuidas de manera exponencial. La longitud de un proceso que puede ser pensado como una secuencia de varias tareas independientes es mejor modelada por una variable después de la Distribución Erlang (que es la distribución de la suma de varias variables distribuidas exponencialmente independientes).
La fiabilidad y la teoría ingeniería de confiabilidad también hacen un amplio uso de la distribución exponencial. Debido a la sin memoria característica de esta distribución, es muy adecuado para modelar la constante porción tasa de riesgo de la curva de la bañera utilizada en la teoría fiabilidad. También es muy conveniente, ya que es tan fácil de añadir las tasas de fracaso de un modelo de fiabilidad. Sin embargo, la distribución exponencial no es apropiado para modelar el curso de la vida en general de los organismos o dispositivos técnicos, porque las "tasas de fracaso" aquí no son constantes: más fracasos ocurren por muy jóvenes y para los sistemas muy antiguos.
En la física , si observa un gas a una determinada temperatura y presión en un uniforme campo gravitatorio, las alturas de las diversas moléculas también siguen una distribución exponencial aproximada. Esto es una consecuencia de la propiedad entropía se menciona a continuación.
Propiedades
Media y varianza
La media o valor esperado de una variable aleatoria distribuida exponencialmente X con parámetro de tasa λ es dado por
![\ Mathrm {E} [X] = \ frac {1} {\ lambda}. \!](../../images/77/7761.png)
A la luz de los ejemplos dados anteriormente, esto tiene sentido: si recibe llamadas de teléfono a una tasa promedio de 2 por hora, entonces usted puede esperar que esperar media hora para cada llamada.
La varianza de X está dada por
![\ Mathrm {} Var [X] = \ frac {1} {\ lambda ^ 2}. \!](../../images/77/7762.png)
Memorylessness
Una propiedad importante de la distribución exponencial es que es sin memoria. Esto significa que si al azar una variable T se distribuye de manera exponencial, su obedece probabilidad condicional
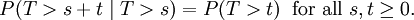
Esto dice que la probabilidad condicional de que tenemos que esperar, por ejemplo, más de otros 10 segundos antes de la primera llegada, dado que la primera llegada aún no ha sucedido después de 30 segundos, no es diferente de la probabilidad inicial que tenemos que esperar más de 10 segundos por primera llegada. Esto es a menudo mal entendida por los estudiantes que toman cursos en la probabilidad: el hecho de que P (T> 40 | T> 30) = P (T> 10) no quiere decir que los eventos T> 40 y T> 30 son independiente. Para resumir: "memorylessness" de la distribución de probabilidad del tiempo de espera T hasta que los primeros medios de llegada
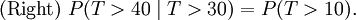
Esto no significa
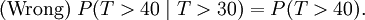
(Eso sería la independencia. Estos dos eventos no son independientes.)
Las distribuciones exponenciales y la distribuciones geométricas son las únicas distribuciones de probabilidad sin memoria.
La distribución exponencial también tiene una constante función de riesgo.
Los cuartiles
La función cuantil (función de distribución acumulada inversa) para Exponencial (λ) es
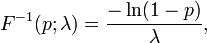
para 0 ≤ p <1. El cuartiles son, por tanto:
- primer cuartil
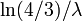
- mediana
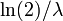
- tercer cuartil
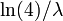
Kullback-Leibler
El dirigida Kullback-Leibler divergencia entre Exp (λ 0) ("verdadero" distribución) y Exp (λ) ('aproximar' distribución) está dada por
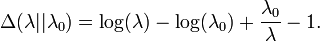
Distribución máxima entropía
Entre todas las distribuciones de probabilidad continuas con el apoyo [0, ∞) y μ decir, la distribución exponencial con λ = 1 / μ tiene la más grande entropía.
Distribución del mínimo de variables aleatorias exponenciales
Sea X 1, ..., X n ser variables aleatorias distribuidas exponencialmente independientes con parámetros de velocidad de λ 1, ..., λ n. Entonces
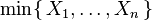
También tiene una distribución exponencial, con el parámetro
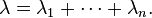
Sin embargo,
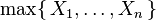
no se distribuye de manera exponencial.
La estimación de parámetros
Supongamos que usted sabe que una determinada variable se distribuye de forma exponencial y se desea estimar el parámetro de tasa λ.
Máxima verosimilitud
La función de verosimilitud para λ, da un muestra independiente e idénticamente distribuidos x = (x 1, ..., x n) a partir de la variable, es
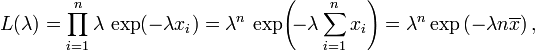
donde
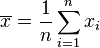
es la media de la muestra.
La derivada de logaritmo de la función de verosimilitud es
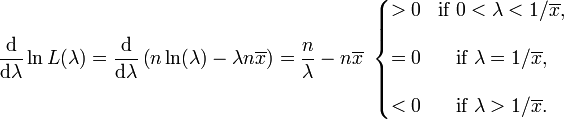
En consecuencia, la estimación de máxima verosimilitud para el parámetro de velocidad es
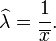
Inferencia bayesiana
La conjugado previa para la distribución exponencial es la distribución gamma (de los cuales la distribución exponencial es un caso especial). La siguiente parametrización del pdf gamma es útil:
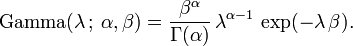
La distribución a posteriori p puede entonces ser expresada en términos de la función de probabilidad definido anteriormente y un gamma antes:
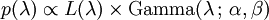
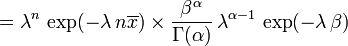
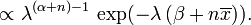
Ahora el p densidad posterior se ha determinado hasta un constante normalizadora desaparecidos. Ya que tiene la forma de un pdf gamma, esto puede ser fácilmente rellenado, y se obtiene
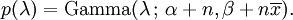
Aquí los parámetros α pueden interpretarse como el número de observaciones anteriores, y β como la suma de las observaciones anteriores.
Generación de variables aleatorias exponenciales
Un método conceptualmente muy simple para la generación exponencial variables aleatorias se basa en transformada inversa de muestreo: Dada una variable aleatoria U trazada desde el distribución uniforme en el intervalo unidad 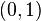 , La variable aleatoria
, La variable aleatoria
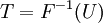
tiene una distribución exponencial, donde 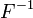 es la función cuantil, definido por
es la función cuantil, definido por
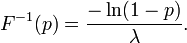
Además, si T es uniforme en 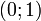 , También lo es
, También lo es 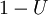 . Esto significa que uno puede generar variables aleatorias exponenciales como sigue:
. Esto significa que uno puede generar variables aleatorias exponenciales como sigue:
{kind=link}
Otros métodos para generar variables aleatorias exponenciales son discutidos por Knuth y Devroye.
La algoritmo zigurat es un método rápido para la generación de variables aleatorias exponenciales.
Distribuciones Relacionados
- Una distribución exponencial es un caso especial de una distribución gamma con
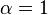 (O
(O 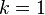 en función del conjunto de parámetros utilizados).
en función del conjunto de parámetros utilizados). - Tanto una distribución exponencial y una distribución gamma son casos especiales de la distribución de tipo fase.
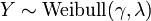 , Es decir, Y tiene una Distribución de Weibull, si
, Es decir, Y tiene una Distribución de Weibull, si 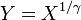 y
y 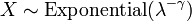 . En particular, cada distribución exponencial es también una distribución de Weibull.
. En particular, cada distribución exponencial es también una distribución de Weibull. 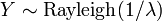 , Es decir, Y tiene una Distribución de Rayleigh, si
, Es decir, Y tiene una Distribución de Rayleigh, si 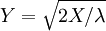 y
y 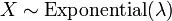 .
. 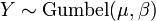 , Es decir, Y tiene una Distribución Gumbel si
, Es decir, Y tiene una Distribución Gumbel si 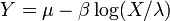 y .
y . 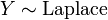 , Es decir, Y tiene una Distribución de Laplace, si
, Es decir, Y tiene una Distribución de Laplace, si 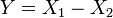 para dos distribuciones exponenciales independientes
para dos distribuciones exponenciales independientes 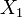 y
y 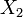 .
. 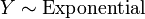 , Es decir, Y tiene una distribución exponencial si
, Es decir, Y tiene una distribución exponencial si 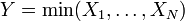 para distribuciones exponenciales independientes
para distribuciones exponenciales independientes 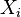 .
. 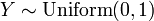 , Es decir, Y tiene una distribución uniforme si
, Es decir, Y tiene una distribución uniforme si 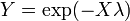 y .
y . 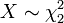 , Es decir, X tiene una distribución chi-cuadrado con 2 grados de libertad, de ser
, Es decir, X tiene una distribución chi-cuadrado con 2 grados de libertad, de ser 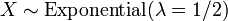 .
. - Dejar
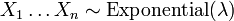 ser distribuidos de manera exponencial e independiente y
ser distribuidos de manera exponencial e independiente y 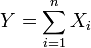 . Entonces
. Entonces 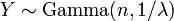
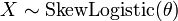 , A continuación,
, A continuación,