
{kind=link}
Codage des caractères
- Pour l'action de cacher le sens de l'information, voir chiffrement.
En télécommunications et en informatique, un jeu de caractères codés est un code qui associe un jeu de caractères abstraits d’un ou plusieurs systèmes d’écriture (comme des alphabets ou des syllabaires) utilisés pour transcrire des langues naturelles avec une représentation numérique pour chaque caractère de ce jeu, ce nombre pouvant lui-même avoir des représentations numériques différentes. Par exemple, le code Morse (qui associe l’alphabet latin à une série de pressions longues et de pressions courtes sur le manipulateur morse du télégraphe) et le code ASCII (qui code les lettres, les chiffres et d'autres symboles comme des entiers codés sur 7 bits) sont des jeux de caractères codés.
Il est indispensable, pour l'échange d'information sur l'Internet, par exemple, de préciser le codage utilisé. Ne pas le faire peut rendre un document difficilement lisible (remplacement des lettres accentuées par d'autres suites de caractères connu sous le nom de mojibake). Toutefois, la convergence vers un standard commun devrait enfin répondre à ce problème.
Dans certains contextes (en particulier dans les communications et dans l'utilisation de données informatiques), il est important de distinguer un répertoire de caractères, qui est un jeu complet de caractères abstraits qu'un système supporte, et un jeu de caractères codés ou codage de caractères qui spécifie comment représenter un caractère en utilisant un entier.
Principe
Le codage des caractères est une convention qui permet, à travers un codage connu de tous, de transmettre de l'information textuelle, là où aucun support ne permet l'écriture scripturale.
Cela consiste à représenter chaque caractère, par un motif visuel, un motif sonore, ou une séquence abstraite. Les techniques des ordinateurs reposent sur l’association d'un caractère à un nombre, et/ou à un ou plusieurs codets.
D'autres techniques permettent, en utilisant un jeu restreint de caractères, d'en coder un plus grand nombre, ou de coder des octets qui peuvent en coder un plus grand nombre, notamment les bien connus Quoted printable, Entité de caractère et Percent-encoding (en) (défini par le RFC 1738).
Différence entre jeu de caractères codés et forme de codage
Le terme jeu de caractères codés est parfois confondu avec la façon dont les caractères sont représentés par une certaine séquence de bits, ce qui implique une forme de codage où le code entier est converti en un ou plusieurs codets (c’est-à-dire des valeurs codées) entiers qui facilitent le stockage dans un système qui gère les données par groupe de bits de taille fixe ou variable.
Par exemple le codage morse utilise un codage ternaire, dont deux des trois codets (impulsion courte ou longue) sont utilisés en groupes pour coder chaque valeur codée, le troisième (une pause plus longue) étant utilisé pour séparer les caractères.
De même, les entiers plus grands que 65535 ne peuvent pas être représentés sur 16 bits, c'est pourquoi la forme de codage UTF-16 représente ces grands entiers comme des couples d’entiers inférieurs à 65536 mais qui ne sont pas associés isolément à des caractères (par exemple, U+10000 - en hexadécimal - devient la paire 0xD800 0xDC00). Ce plan de codage convertit alors les valeurs de ces codes en une suite de bits et ce en prenant garde à un certain nombre de contraintes comme la dépendance vis-à-vis de la plateforme sur l'ordre final des octets (par exemple, D800 DC00 devient 00 D8 00 DC sur une architecture Intel x86). L'Unicode Technical Report #17 explique cette terminologie en profondeur et fournit davantage d'exemples.
Une page de code abrège ce procédé en associant directement aux caractères abstraits des séquences de bits spécifiques de taille fixe (généralement 7 ou 8 bits par caractère).
Internationalisation
Les limites du standard américain ASCII ont conduit, sur trois périodes différentes, à trois approches de l'internationalisation :
- L'utilisation de standards régionaux à caractères-monooctets, techniquement les plus faciles à mettre en place ;
- L'utilisation de standards extensibles, où un même octet peut représenter un caractère différent suivant le contexte (famille ISO 2022) ainsi que des extensions où un caractère est codé sur plusieurs octets ;
- L'utilisation du Standard Unicode (famille UTF), qui est celui qui comprend le plus grand nombre de caractères.
Les standards régionaux ont l'inconvénient de ne permettre la représentation que d'un ensemble réduit de caractères, comme les caractères d'Europe occidentale. Avec cette approche, il est nécessaire d'indiquer l'encodage à l'extérieur du flot.
Les standards ISO 2022 ont l'inconvénient d'être contextuels. Il se peut que des logiciels utilisant certains algorithme de recherche manque d'interopérabilité à cet égard.
Les formes de codage définies par Le Standard Unicode ont l'inconvénient de la présence éventuelle de la fonctionnalité d'indicateur d'encodage en début de flot, qui le cas échéant est introduit par le caractère Byte Order Mark. Certains logiciels anciens ne sont pas compatibles avec la présence de ces trois octets, et ne pourront pas l'être en raison de la complexité conceptuelle que représente le fait de traiter ces trois octets. En particulier, certaines opérations deviennent plus complexes comme la concaténation de chaînes.
Historique
Premiers codages de caractères
| "NON" |  |  | |
Les premiers codages de caractères permettaient de s'affranchir de la distance. Ils utilisaient des techniques visuelles variées, mais ne codaient pas l'information sous forme binaire.
- Code international des signaux maritimes. Il s'agit de transmission visuelle, basée sur une séquence de drapeaux.
- Tour Chappe (1794). Il s'agit de transmission visuelles par positionnement des bras du télégraphe dans différentes postures.
- Alphabet Morse (1838). Il a été inventé en 1832 pour la télégraphie. Il est basé sur des séquences courtes et des séquences longues. Il permet de transmettre des textes non accentuées, mais n'est pas limité en longueur, rendant des extensions possibles.
- Le télégraphe chinois convertissait les texte chinois avec des pages de codes en séquences de quatre chiffre décimaux, chiffres transmis en Morse.
Codage par séquence de bits

Les premiers codages binaires de caractères furent introduits en France par l'ingénieur Mimault et par le Code Baudot pour le Télex et aux États-Unis par des sociétés répondant aux appels d'offres de l'État fédéral. Pour le recensement puis des besoins particuliers.
Code Baudot (1874) : 32 codes (5 bits). Il permettait de transmettre des caractères non accentués et ne servait que pour le Telex.
Il permettait de transmettre les vingt-six lettres non accentuées, les dix chiffres, ainsi qu'une douzaine de symboles supplémentaires.
Vers 1901, le code Baudot original a été modifié par Donald Murray qui réorganisa les caractères, ajouta de nouveaux symboles, et introduisit les jeux de caractères.
Codage industriel, mécanique et télécommunications

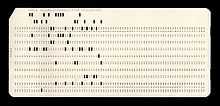
En 1890, on répartit les perforations arbitrairement sur la carte (recensement Hollerith 1890)[1].
En raison de l'existence de brevets le codage Hollerith de IBM n'est pas utilisé par Bull. Ce manque d'interopérabilité fragmenta le marché entre "clients IBM" et "clients Bull".
Vers le changement de siècle développement d'un codage performant sur cartes perforées pour le recensement étatique. Le produit fut ensuite commercialisé par le Tabulating Machine Co.[2].
- Western Union en utilisa une version modifiée jusque dans les années 1950. Avaient été rajoutées l'espace et la sonnerie.
- Dans les années 1930, le CCITT a introduit le International Telegraph Alphabet No. 2 (ITA2) code comme standard international, basé sur le code Western Union modifié. Les États-Unis ont standardisé une version de l'ITA2 comme American Teletypewriter code (USTTY) qui était une base de codes 5-bit teletypewriter jusqu'aux débuts de l'ASCII 7 bits en 1963.
Informatisation
En 1948, Manchester Mark I, le premier ordinateur électronique, utilisait les principes du Code Baudot.
- RADIX-50 (1959) : 40 codes, stocke 3 caractères dans un mot de 16 bits en big endian (PDP-11). Il permet de stocker les dix chiffres, l'espace, vingt-six lettres, et les trois symboles «.», «$», «%».
- SIXBIT (1968 et 1954) : 64 codes (6 bits), stocke six bits caractères par mot mémoire (PDP-10).
Six-bit BCD était utilisé par IBM sur les premiers ordinateurs comme le IBM 704 en 1954[3]. Par la suite, il donne naissance à l'EBCDIC.
Voir aussi BCD (6-bit) et Fieldata.
Les années 1960

En 1960, IBM, Univac, Burrough, Honeywell et d'autres, se sont regroupés en consortioum pour définir un standard commun[4] .
Dans les années 1960, dans un contexte de guerre froide, apparaissent le GHOST et l'ASCII.
- 1963 : naissance de l'ASCII dans le bloc des États-Unis. Prise en charge des caractères latins et anglais, sur sept bits. Dépassement de la limite précédente de six bits.
- 1963 : naissance de l'Extended Binary Coded Decimal Interchange Code ( EBCDIC) sur 8-bit.
- 1964 : naissance du GOST (pour Государственный стандарт, norme d'État) dans le bloc soviétique GOST 10859. Prise en charge des caractères cyrilliques et anglais.
- 1968 : naissance de MARC-8 (en) permettant de coder 15 000 caractères.
Naissance de l'ASCII
En juillet 1971, le RFC 183, «The EBCDIC Codes and Their Mapping to ASCII» pose les bases de la conversion à l'ASCII, pour limiter les caractères utilisés.
Le standard ASCII (American Standard Code for Information Interchange) comporte 128 codes (7 bits). Quelques valeurs courantes :
- ASCII 10 : Saut de ligne abrégé « LF » pour Line Feed ;
- ASCII 32 : Espace ;
- ASCII 65 : Lettre A majuscule.
ASCII est standardisé en 1968 sous le nom « ANSI X3.4-1968 ». Puis les mises à jour suivent : ANSI X3.4-1977 et finalement ANSI X3.4-1986. On peut enfin le rencontrer sous le nom « US-ASCII ». Il existe en fait des dizaines de variantes de l'ASCII, mais c'est essentiellement la signification des codes de contrôles (caractères non imprimables) qui change.
Évolutions de l'ASCII vers les jeux de caractères codés sur 8 bits et la norme ISO 8859
Les variantes d'origine
Le premier codage largement répandu fut l'ASCII. Pour des raisons historiques (les grandes sociétés associées pour mettre au point l'ASCII étaient américaines) et techniques (7 bits disponibles seulement pour coder un caractère), ce codage ne prenait en compte que 27 soit 128 caractères. De ce fait, l'ASCII ne comporte pas les caractères accentués, les cédilles, etc. utilisés par des langues comme le français. Ceci devint vite inadapté et un certain nombre de méthodes ad-hoc furent utilisées d’abord pour le modifier. Ainsi sont apparues des variantes multiples du codage ASCII, adaptées à des langues ou groupes de langues limités.
En 1972, pour mettre fin à leur profilération, l'ISO a d’abord créé la norme ISO/CEI 646 formalisant un code normalisé sur 7 bits, où des positions ont été désignées comme invariantes, et quelques-unes étaient autorisées à désigner d'autres caractères. Ce système a vite eu ses limites, car il n’était adapté qu'à un petit nombre de langues à écriture latine, et il y manquait de trop nombreux caractères, et ne permettait pas de représenter les écritures non latines.
Modification dynamique par séquence d'échappement
Différentes solutions ont été envisagées : d’abord définir un système permettant de modifier dynamiquement le jeu de caractère codé utilisé ou le groupe de caractères utilisé dans une écriture complexe. Ce système a pu fonctionner pour conserver la compatibilité avec les systèmes de communication restreints à 7 bits, et a donné lieu aux standards comme le Videotex ou les premiers systèmes de Télétexte, et reprenait en fait l’idée déjà en place pour les télex.
De leur côté, les pays asiatiques orientaux ont développé un système hybride utilisant des pages de code multiples, avec différentes représentations binaires selon que le système permettait de stocker les octets sur 8 bits ou sur 7 bits. L’ISO a aussi mis en place une norme destinée à leur interopérabilité, la norme ISO 2022, et pour l’Internet, l’IANA a mis en place un registre permettant de référencer tous ces codages.
Imposition du 8 bits
Mais avec le développement des protocoles de communication sur Internet basés sur 8 bits, mais aussi pour les nombreux logiciels écrits en langues occidentales, il est apparu plus simple (au départ) de n’avoir à coder les caractères que sur un seul octet. Divers systèmes sont apparus d’abord sur des systèmes incompatibles entre eux, par exemple entre les premiers PC d’IBM et d’Apple (utilisant une puis de nombreuses pages de code), mais aussi les ordinateurs familiaux de divers marques, les imprimantes, le langage Postscript, ou encore les classiques mainframes d’IBM qui utilisaient encore l’EBCDIC sur une partie seulement des valeurs possibles sur 8 bits (avec là aussi de nombreuses variantes nationales mais dont les positions inutilisées depuis l’abandon du codage décimal des anciennes cartes perforées ont été utilisées pour étendre le jeu de caractères), ou encore les premiers systèmes Unix dont un produit par Digital Equipment Corporation (DEC) fera date en étant le vrai premier jeu de caractères « multinational » (le Multinational Character Set ou MCS) pour les langues à écriture latine, une idée qui sera aussi reprise aussi dans le développement de pages de codes nationales pour PC dans les premières versions de MS-DOS (produites par Microsoft et non IBM comme auparavant).
Ce développement a également eu lieu pour plusieurs autres écritures, mais avec de nombreuses variantes même au sein de chaque écriture : Apple popularisera le jeu de caractères codés MacRoman sur ses premiers Macintosh ainsi qu'une dizaine d’autres jeux similaires pour divers groupes de langues ou systèmes d’écriture, tandis que sur les PC subsisteront des pages de codes « multinationales » plus complètes mais encore insuffisantes pour couvrir convenablement les langues de plusieurs pays proches, et même parfois au sein de la même langue (par exemple entre les langues latines d’Europe occidentale, celles d’Europe centrale, et d’autres encore pour répondre aux besoins spécifiques de divers pays).
L’Union soviétique quant à elle, n’a pas accès officiellement aux systèmes d’exploitation développés essentiellement aux États-Unis en raison de l’embargo technologique à la fin de la Guerre froide (et donc pas aux discussions et décisions liées à leur développement) et développe sa propre norme KOI8-R pour l’écriture cyrillique en russe, et parvient à l'imposer en Bulgarie et en ex-Yougoslavie pour l’écriture cyrillique du serbo-croate, ainsi que dans d’autres pays utilisant cette écriture. Pour l’Ukraine elle crée une variante KOI8-U destinée à la langue ukrainienne, au départ utilisés sur les systèmes gouvernementaux bien avant que les PC s’imposent chez les particuliers. Ces jeux de caractères codés auront finalement (et ont encore) plus de succès que les pages de codes pour DOS développées par IBM et Microsoft, même dans les pays non soumis à l’embargo américain et qui commencent à utiliser aussi les PC d’IBM et MS-DOS, ou les jeux de caractères cyrilliques utilisés sur les premiers Macintosh d’Apple (souvent encore trop chers pour ces marchés).
En raison de l'utilisation de certains caractères locaux pour des programmations informatiques, une grande incohérence entre pays francophones est apparue. En 1983, cette incohérence a conduit la France a abandonner sa norme Z62010 au profit de l'Ascii.
Face à ce désordre qui nuisait à l'interopérabilité, l’ISO a développé une norme mieux étudiée, la norme ISO/CEI 8859, selon les principes des pages de code DOS mais cette fois compatible avec ISO 646 et ISO 2022, mais là encore avec de multiples variantes, adaptées à des groupes de langue plus étendus qu'avec les pages de code pour PC. Une de ces variantes la plus connue est la page de code ISO/CEI 8859-1, développée sur la base du jeu de caractères MCS de DEC qui lui-même était basé sur la variante américaine (ASCII) du jeu ISO 646 normalisé mais seulement pour les langues européennes occidentales (le jeu dit « latin-1 »), les autres variantes étant créées de façon à réutiliser si possible les mêmes positions pour des caractères identiques ou proches lexicographiquement (cela n’a pas toujours été vrai pour toutes les variantes latines ISO/CEI 8859-2, etc. jusqu'à ISO/CEI 8859-13), y compris pour d’autres écritures à alphabet simples (grec, cyrillique, arabe, thaï).
Microsoft Windows intégrera cependant les caractères de la norme ISO 8859 en abandonnant les caractères de contrôle supplémentaires codés au-delà des 128 premiers caractères ASCII (Windows abandonne toute idée d'interopérabilité avec EBCDIC), pour y coder quelques autres signes de ponctuation ou lettres manquantes dans certains des volets de la norme ISO 8859 (puis en ajouter quelques autres, notamment le symbole de l’euro en 1998), réduisant ainsi le nombre de variantes nécessaires (notamment pour l’écriture latine), mais introduisant des problèmes d'intéropérabilité notamment au niveau du symbole euro.
Émergence des systèmes multilingues
TRON Character Code et TRON Multilingual Environment
Le Japon, qui a des besoins spécifiques a proposé un jeu de caractères multi-culturel dans la première moitié des années 1980s. Il s'agissait de projet TRON lancé en 1984.
Aujourd'hui, le TRON inclut les codages suivants :
- BTRON3 Character Sets (Partial) ;
- ISO 8859-1 ;
- GB 2312-80 ;
- JIS X 0208-1990 ;
- JIS X 0212-1990 ;
- KS C 5601-1992 ;
- Six-dot braille ;
- Eight-dot braille.
MULE et Emacs
Dans la communauté Unix, le support des textes écrits dans des langues différentes était opéré à travers le logiciel MULE (en) d'Emacs à partir de 1993[2]. Le système MULE prend en charge le ISO-2022-JP décrit dans le RFC 1554[5].
Évolutions vers un jeu de caractères codés universel
De son côté, l’Inde a créé sa propre norme ISCII. La norme ISCII a été créée pour assurer la bonne interopérabilité d'une dizaine de jeux de caractères nécessaires pour autant de systèmes d’écriture différents. Elle aurait pu rentrer dans la norme ISO 8859 si l’ISCII avait utilisé la norme ISO 2022 pour basculer d’un jeu à l’autre ; de toute façon une telle intégration mise à jour de l’ISCII pour assurer cette compatibilité aurait plus nuit à l'interopérabilité des écritures indiennes, l’Inde ayant depuis aussi décidé que toute nouvelle extension se ferait via le jeu de caractères universel en développement et activement supporté par l’Inde. Il devenait urgent de définir un jeu de caractères codés dit « universel ».
L’ISO met en place un comité technique, mais tarde à publier sa norme (ISO/CEI 10646), et de plus un autre organisme de normalisation privé (le Consortium Unicode) se met en place sous l’impulsion de plusieurs éditeurs de logiciels : son but est de rendre utilisable le jeu de caractères universel en ajoutant des propriétés, mais dans un premier temps les deux organismes ne se mettent pas d'accord sur le codage de l’hangul (l’alphabet utilisé pour transcrire le coréen). De plus Unicode ne croit pas au début que plus de 65536 caractères seront nécessaires dans un seul plan, le consortium n’ayant au départ comme objectif que de couvrir que les systèmes d'écritures des langues modernes (les plus économiquement rentables), afin de les coder le plus rapidement possible.
La norme Unicode 1.0 voit le jour, mais est en partie incompatible avec la première version de l’ISO 10646, ce qui freine finalement le développement (d’autant que le Consortium Unicode convient rapidement que plus d’un plan sera finalement nécessaire, en observant les travaux de codification des sinogrammes faits par un comité technique spécifique UniHan). Différentes solutions sont envisagées et UTF-16 est expérimenté (mais pas encore standardisé par Unicode, ni approuvé dans la norme ISO/CEI 10646), tandis qu’apparaissent d’autres difficultés techniques d’interopérabilité avec UTF-32 (dont le développement initial a lui aussi connu plusieurs variantes) et UTF-8 (l’ISO/CEI 10646 en normalise une variante légèrement différente de celle définie par le standard Unicode !).
De leur côté, les systèmes d'exploitation et logiciels pour PC ou Mac ne sont pas encore prêts à supporter des jeux de caractères codés sur plusieurs octets, et d’autres variantes de l’ISO 8859 voient le jour, par exemple l’ISO/CEI 8859-14 (nécessaire pour les langues celtiques dont l’irlandais, une des langues officielles de l‘Union européennes), l’ISO/CEI 8859-15 (introduisant en 1998 le symbole € de l’euro qui allait devenir la monnaie unique d’une douzaine de pays de l’Union européenne), et l’ISO/CEI 8859-16 (palliant l'absence de caractères nécessaires à la transcription correcte du roumain, à savoir des caractères utilisant une virgule souscrite et non une cédille).
Ce sera la dernière partie ajoutée à l’ISO 8859, l’ISO estimant que les besoins pour les autres langues étaient déjà couverts par les autres normes nationales (ISCII en Inde, VISCII au Viet Nâm, GB2312 en Chine, EUC-JP au Japon, etc.) et préférant se consacrer au développement du jeu de caractères universel plutôt que d'en définir de nouveaux, codés sur 7 ou 8 bits et complètement incompatibles avec ceux déjà largement déployés dans ces pays, les autres pays ayant déjà décidé d’adopter pour leurs langues directement le jeu universel de caractères codés. Cet abandon sera d’autant plus facilité que les normes ISO 10646 et Unicode ont rapidement décidé de fusionner leurs répertoires et y sont parvenues rapidement en produisant une mise à jour majeure pour Unicode 1.1 (rendant obsolète la version 1.0 du standard Unicode incompatible, mais en intégrant la forme de codage UTF-16 en tant que partie intégrante de son standard) et ISO 10646-1 (compatible avec ISO 10646, mais en abandonnant l’idée de supporter à l’avenir plus de 17 plans, et en acceptant d’intégrer et normaliser UTF-16), et en créant des procédures permettant aux deux comités techniques de collaborer et assurer leur coordination. De plus les systèmes d’exploitation, logiciels, polices de caractères et protocoles pour l’Internet ont également évolué pour accepter nativement le jeu universel.
La norme ISO 10646 qui définit le jeu de caractères universel (conjointement avec le standard Unicode lui ajoutant des propriétés facilitant le traitement) a largement réussi son ambition de coder la majorité des systèmes d’écriture utilisés dans le monde (il reste encore à coder quelques écritures complexes ou mal connues), et conserve son ambition de couvrir toutes les écritures utilisées dans l’histoire de l’humanité (donc y compris les écritures anciennes, ou des caractères rares dans des écritures déjà codées, ou de nouveaux caractères qui apparaîtraient dans l’usage courant dans certains pays du monde ou qui seraient rendus nécessaires pour certains traitements afin de lever des ambiguïtes).
Le répertoire universel (d’ISO 10646-1 et Unicode) contenait en fin 2009 environ 100 000 caractères (dont plus de la moitié pour les seuls sinogrammes), chacun possédant un unique code entier compris entre 0 et 10FFFF en hexadécimal (soit un peu plus de 1,1 million - il existe donc des entiers auxquels aucun caractère n'est associé). Deux autres répertoires fréquemment utilisés, les jeux de caractères codés ASCII (ISO 646, dans sa dernière variante américaine normalisée en 1984) et ISO 8859-1, sont respectivement identiques aux 128 et 256 premiers caractères codés dans ce répertoire universel.
Retour aux plages réduites
La popularisation des messages courts de 160 octets, dits SMS, de par leur taille réduite et leur coût, a conduit à la réapparition des techniques de codage de texte sur des bytes courts de sept bits. (GSM 03.38 (en)).
Jeux de caractères codés populaires, par pays
Sur Internet, l'UTF-8 et l'ASCII sont les deux encodages les plus populaires depuis 2010[6]. En juillet 2012, leur utilisation est estimée à 80 %, (65 % + 15 %) contre 10 % environ pour les encodages occidentaux (latin1). L'utilisation des autres encodages est inférieure à 10 % sur internet.
Amérique
États-Unis
- ISO 646 ;
- ASCII.
Canada
- ASCII, standard de compatibilité, sans accent ;
- ISO 8859-1 ;
- Unicode, voir aussi UTF-8.
Europe
Union européenne
- UTF-8, notamment utilisé par http://www.europa.eu/.
France
- ISO 646-variante de référence internationale (IRV, alias ASCII), standard de compatibilité, sans accent, pour le développement de logiciel en anglais ;
- « Jeu de caractères graphiques français pour la langue française », 94 caractères codés sur 7 bits, normalisé ISO/CEI 646-69 le 1er juin 1983, et normalisé AFNOR NF Z 62 010 en 1982. Aujourd'hui désuet, mais activable par séquence d'échappement ;
- standard de compatibilité ;
- dans l'une de ses deux variantes françaises (AFNOR) ;
- standard du minitel (voir viewdata) ;
- ISO-2022 peu utilisé en France mais reprend tous les caractères français ;
- CP850 à l'époque du DOS ;
- Windows-1252, originaire de Microsoft Windows, encore appelé CP1252 ou Ansinew ;
- ISO 8859-1, avant l'euro ;
- ISO 8859-15, après l'euro ;
- Unicode, voir aussi UTF-8 (reprend tous les caractères des jeux de code précédent).
Historique des codages de caractères français
| Code Baudot | ||||
| ↓ | ||||
| (IA2) | ||||
| EBCDIC | ||||
| ↓ | ||||
| ISO-646 - IRV | ||||
| ↓ | ↓ | ↓ | ↓ | |
| ISO-646 - US | ||||
| ISO-646- FR-0 025 AFNOR NF Z 62010-1973 | ||||
| ↓ | ||||
| ISO/CEI 646-69 le 1er juin 1983, et normalisé AFNOR NF Z 62 010 en 1982. | ||||
| ↓ | ↓ | ↓ | ↓ | |
| ASCII | CP850 à l'époque du DOS. | |||
| ↓ | ↓ | ↓ | ||
| Windows-1252, originaire de Microsoft Windows, encore appelé CP1252 ou Ansinew | ISO 8859-1, avant l'euro | |||
| ↓ | ↓ | |||
| ISO 8859-15, après l'euro | ||||
| ↓ | ↓ | ↓ | ↓ | |
| ISO 10646 / Unicode | ||||
| ↓ | ||||
| IA 5 | ||||
| ↓ | ||||
↑ → ↓
Grèce
- UTF-8 ;
- ISO 8859-7 (sans l’euro).
Roumanie
- ISO 8859-2 ;
- ISO 8859-16 ;
- UTF-8.
Lituanie
- Windows-1257, pour Windows, utilisé par http://www.lrv.lt/ ;
- UTF-8, utilisé pour la langue française par http://www.president.lt/fr/.
Russie
- KOI8-R ;
- UTF-8.
Ukraine, Bulgarie
- KOI8-U ;
- UTF-8.
Afrique
Maghreb
- UTF-8, utilisé sur http://www.maroc.ma/portailinst/Ar ;
- Windows-1256, utilisé par exemple par http://www.almaghribia.ma/.
Asie
- ISCII (alphasyllabaires utilisés en Inde, au Sri Lanka et au Bangladesh) ;
- VISCII (alphabet latin moderne du vietnamien) ;
- TIS-620 (écriture thaïe) ;
- KSC 5601 (alphabet hangûl du coréen) ;
- GB18030 (écriture sinographique simplifiée des langues chinoises) ;
- Big5 (écriture sinographique traditionnelle des langues chinoises) ;
- Shift-JIS (syllabaires et écriture sinographique traditionnelle des langues japonaises).
Autres codages de caractères populaires
- Codage SMS ;
- ISO 646 : ASCII ;
- EBCDIC ;
- ISO 8859 : ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859-9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15, ISO 8859-16 ;
- Jeux de caractères codés DOS : CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 ;
- Jeux de caractères codés Windows : Windows-1250, Windows-1251, Windows-1252, Windows-1253, Windows-1254, Windows-1255, Windows-1256, Windows-1257, Windows-1258 ;
- VISCII ;
- KOI8-R, KOI8-U ;
- TIS-620 ;
- ISCII ;
- ISO 2022, EUC ;
- Big5 : HKSCS ;
- Guobiao : GB2312, GBK, GB18030 ;
- Shift-JIS ;
- ISO/CEI 10646 : Unicode, voir aussi UTF-8.
Notes et références
- ↑ http://www.kerleo.net/computers/mecanographie.htm
- 1 2 Steven J. Searle, « A Brief History of Character Codes in North America, Europe, and East Asia », Sakamura Laboratory, University Museum, University of Tokyo,
- ↑ (en) IBM Corporation, 704 electronic data-processing machine : manual of operation, (lire en ligne), p. 35
- ↑ Jacques André, « Caractères, codage et normalisation : de Chappe à Unicode », Document numérique, Lavoisier, vol. 6, no 3-4 « Unicode, écriture du monde ? », , p. 13-49 (ISBN 2-7462-0594-7, lire en ligne)
- ↑ http://www.ietf.org/rfc/rfc1554.txt
- ↑ http://spectrum.ieee.org/telecom/standards/will-unicode-soon-be-the-universal-code
Voir aussi
Bibliographie
- (en) Eric Fischer, The Evolution of Character Codes, 1874-1968, , 33 p. (présentation en ligne, lire en ligne)
- Comité consultatif international télégraphique et téléphonique, Alphabet international de référence (ancien alphabet international n° 5 ou AI5) : Technologie de l'information – Jeux de caractères codés à 7 bits pour l'échange d'informations, Union internationale des télécommunications, coll. « Recommandations / Série T » (no T.50 (09/92)), , 22 p. (présentation en ligne, lire en ligne)
- (en) Victor Stinner, Programming with Unicode, (présentation en ligne, lire en ligne), chap. 5 (« Charsets and encodings »)
Liens externes
- (en) Character Sets, sur le site de l'Internet Assigned Numbers Authority
- (en) Unicode Character Encoding Model, sur le site du Consortium Unicode
- (en) The Punched Card, sur la page personnelle de John Savard
 Portail de l’informatique
Portail de l’informatique  Portail de l’écriture
Portail de l’écriture