
Traçabilité (informatique)
En développement de logiciel, l’exigence de traçabilité est définie comme « la capacité à suivre la vie d'une exigence, depuis ses origines, à travers son développement, son cahier des charges, son déploiement et son utilisation »[1]. Les liens de traçabilité entre les exigences d'un système et son code source sont utiles pour réduire l’effort de compréhension et de maintenance. Ils sont également essentiels pour assurer la conformité et la mise en œuvre des exigences spécifiées.
Contexte
Causes de la détérioration des liens de traçabilités
Très souvent, au cours de la maintenance et de l'évolution d’un logiciel, les développeurs se concentrent seulement sur la correction des défauts ou des bogues. Le code source évolue mais l'architecture, la conception et la documentation ne sont pas mises à jour. Les liens de traçabilité deviennent alors obsolètes car les développeurs n'ont pas de temps ou ne peuvent pas en consacrer à la mise à jour de ces liens[2]. La récupération des liens de traçabilité devient alors par la suite une tâche ardue et coûteuse.
Récupération des liens de traçabilité
Afin de pallier la détérioration des liens de traçabilité, de nombreux chercheurs ont utilisé des techniques de recherche d’information pour récupérer les liens existants entre des documents de « haut niveau » (exigences du logiciel, documentation ou documents de conception) et des documents de plus « bas niveau » (code source ou diagramme UML).
Ces techniques convertissent tous les documents sous forme textuelle et comparent la similarité entre les artefacts (e.g. code source d’une classe et exigences) de niveaux différents. Un haut taux de similitude signifie que ces deux artefacts partagent les mêmes concepts et sont très probablement liés l’un à l’autre.
Plusieurs métriques sont utilisées afin de mesurer l'efficacité des différentes techniques de récupération des liens de traçabilité. Les plus courantes sont le rappel et la précision. Il existe également une formule appelée F-mesure (en) qui est semblable à une moyenne et qui combine les deux métriques précédentes.
Rappel
Le rappel correspond au rapport du nombre de liens pertinents retrouvés sur l’ensemble des liens pertinents existant. Il permet de mesurer si l'algorithme récupère bien les liens existants.
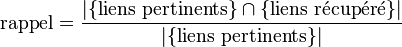
Précision
La précision correspond au rapport du nombre de liens pertinents retrouvés sur l’ensemble des liens retrouvé. Elle mesure l'exactitude des liens retrouvés.

F-mesure
La F-mesure combine la précision et le rappel. Elle est définie comme :
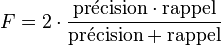
{kind=link}
Différentes approches
Utilisation de la recherche d'information
Les méthodes historiquement utilisées pour la récupération des liens de traçabilité sont basées sur des techniques de recherche d'information. Parmi toutes ces techniques on trouve notamment des solutions reposant sur les modèles vectoriels ou d’autres utilisant des modèles de Jensen–Shannon (en).
Cependant, ces méthodes produisent des résultats approximatifs qui demandent bien souvent d’intervenir manuellement pour évaluer et filtrer les données récupérées. Elles sont le plus souvent composées de matrices de correspondance entre les différents types d’artefacts. Ces matrices doivent cependant être manuellement corrigées lors de leur création et tout au long du processus de développement du logiciel.
Améliorations
Des solutions[3] ont été proposées afin d’améliorer la qualité des résultats produits par les méthodes de recherche d’information. Parmi celles-ci on trouve notamment l’utilisation de phrases[4] ou de termes[5] plutôt qu’une correspondance mot à mot. Dans le même esprit, on peut également utiliser un glossaire[6] pour extraire[4] les termes ou les phrases significatives dans le projet afin de leur donner un poids plus important lors de l’identification des liens de traçabilité.
Maintenance de la traçabilité
Certaines solutions ont été mises au point dans le but d’aider le développeur à maintenir ces liens de traçabilité.
COCONUT
COCONUT[7] (pour “COde Comprehension Nurturant Using Traceability”) se présente sous la forme d’un plug-in pour l'environnement de développement Eclipse. Il permet d’aider les développeurs à utiliser des identifiants (e.g. noms de variables) et/ou à rédiger des commentaires ayant une correspondance forte avec les exigences du système.
Reconnaissance de modifications appliquées au modèle
Dans le cas de développements pilotés par modèle UML il est possible d’analyser les changements effectués sur le diagramme de structure pour mettre à jour automatiquement les liens de traçabilité.
La solution proposée[8] se décompose en trois étapes :
- capture des modifications effectuées sur le modèle et génération d'évènements élémentaires
- reconnaissance des activités de développement relatives à la modification du modèle (par composition de plusieurs changements élémentaires)
- mises à jour des liens de traçabilité associés à l’élément modifié
TraceM
TraceM[9] est un système de gestion de la traçabilité qui utilise les concepts de systèmes hypermédia[10] et d’intégration de l’information (en). Il se présente sous la forme d’un framework qui permet de découvrir les liens de traçabilité implicites grâce aux liens explicitement connus.

TraceM repose sur les concepts suivants :
- un Outil est utilisé pour effectuer une tâche (e.g. EDI, gestionnaire de versions, client mail)
- un Artefact est produit par un Outil
- une Relation est une association sémantique entre des Artefacts, portions d’Artefacts ou d’autres Relations
- les Méta-données sont utilisées par le développeur pour décrire les Artefacts et les Relations créées durant le projet
TraceM supporte la création automatique de liens de traçabilité et permet également d’effectuer des relations entre plusieurs relations existantes.
Recherche dans un ensemble de liens de traçabilité
D’autres approches s’orientent plutôt sur la manière de trouver de l’information parmi les données récupérées. Il existe par exemple un langage dédié à recherche dans un ensemble de liens de traçabilité. TQL[11] (pour “Traceability Query Language”) permet d’effectuer des requêtes du type :
Question: Est-ce que toutes les exigences sont couvertes par un jeu de tests ?
set:difference(Requirement(),
traceFrom(Requirement(),
TestCase()))
Extraction d’informations depuis un gestionnaire de version
Certaines approches basées sur l’heuristique[12] permettent de récupérer/créer des liens de traçabilité entre différents éléments d’un logiciel. Ceci est effectué via l'examen du/des gestionnaire(s) de versions utilisé(s) lors du développement. Ce type d’approche met en œuvre des méthodes d'extraction de motifs séquentiels (en). L'extraction de ces motifs est effectué sur les commits issus du gestionnaire de versions afin de détecter les changements simultanés entre différents fichiers (par exemple entre le code source et la documentation). Si plusieurs fichiers sont très régulièrement modifiés durant les mêmes commits, alors la probabilité d’avoir un lien de traçabilité entre ceux-ci est très forte.
Techniques hybrides
Récupération de l'information orthogonale
Certaines techniques de récupération de liens de traçabilité peuvent produire des résultats complémentaires. Par exemple, des solutions basées sur les modèles vectoriels sont capable de récupérer un plus grand nombre de liens que les techniques empiriques mais possèdent une précision beaucoup plus faible. En se basant sur ce constat certaines méthodes[13] combinent les résultats, dits “orthogonaux”, de différentes techniques pour améliorer le résultat final.
Emplacement d'entité
Sans parler de récupération de liens de traçabilité, il existe des techniques dites de récupération d'information. Cette pratique peut être vue comme un problème de prise de décision en présence d’incertitude.
Une des solutions à ce type de problèmes est l’utilisation de plusieurs systèmes experts[14]. Dans le cas de l’analyse de codes sources il est par exemple possible de combiner deux types d’analyses : statique et dynamique. Alors que l’analyse statique étudie directement le code source de l’application, l’analyse dynamique, quant à elle, effectue des relevés (aussi appelés : traces) lors de l’exécution du programme et analyse ces données.
Trustrace

Trustace[15] est une solution de récupération de liens de traçabilité entre le code source et les exigences du logiciel. C’est une technique qui utilise plusieurs sources d’information hétérogènes pour dynamiquement réévaluer les liens de traçabilité issus des techniques de récupération d’information standards.
Dans un premier temps Trustrace utilise Histrace[16] pour effectuer le forage de données sur les dépôts de code source. Puis, grâce aux données minées il crée de nouveaux liens de traçabilité entre les exigences logicielles et les données annexes du dépôt (e.g. Commits, Bugs, etc.). Ces ensembles de liens sont appelés des experts.
Une fois les ensembles experts construits. Trustrace utilise Trumo[17] et DynWing[17] pour réévaluer les liens de traçabilité issus des systèmes classiques. Des poids sont dynamiquement alloués à chacun des liens. Ces poids sont déterminés en comparant les similitudes entre les liens initiaux avec les liens fournis par les experts et selon sur la fréquence d’apparition de ces liens dans chacun des ensembles d’experts.
Histrace
Histrace permet de créer des liens, entre un ensemble d’exigences et le code source, en utilisant les informations issues d’un dépôt de logiciel (CVS/SVN). Pour cela Histrace considère les descriptions textuelles des exigences, les messages de commits, les rapports de bogues, et les classes comme des documents distincts qu’il utilise pour produire deux ensembles experts. L’un utilise les messages de commit pour établir les liens de traçabilité et le deuxième utilise les rapports de bogues.
Trumo
Trumo est similaire à un modèle de confiance d’utilisateurs : Plus des utilisateurs achètent sur un site Internet plus la confiance des utilisateurs envers celui-ci augmente.
Dans cet esprit Trumo va assigner un poids à chaque liens de traçabilité en se basant sur les similitudes des liens issus des ensemble experts et des résultats des techniques de bases. Pour cela Trumo effectue un premier tri en écartant tous les liens qui ne sont pas à la fois dans les résultats de bases et dans un des ensembles experts. Ensuite un poids est affecté à chaque lien en fonction de ces similitudes au sein des différents ensembles. Finalement, Trumo assigne un poids à chaque experts qui est déterminé par DynWing.
DynWing
Afin de déterminer le poids à affecter à chaque expert, DynWing prend le parti de résoudre cela sous la forme d’un problème de maximisation.
Typiquement, chaque expert à une certaine confiance en chacun des liens qu’il produit. Trumo détermine le poids de chaque lien en fonction de ça similarité et du poids de chaque expert. Pour calculer le poids de chaque expert DynWing va maximiser le poids final de chaque lien (déterminé par Trumo).
Ainsi Trumo et DynWing sont en réalité deux modules très liés qui permettent de réviser la confiance de chaque lien de traçabilité initiaux grâce aux nouveaux liens issus de Histrace.
Limitations actuelles
Dans l’état actuel des choses l’ensemble des techniques proposées pour la la récupération des liens de traçabilité manque d’exactitude. Il semble actuellement difficile d’obtenir un très bon taux de rappel avec un taux de précision correct et inversement proportionnel. Certaines techniques plus récentes, comme Trustrace, utilisant de nouvelles sources d’informations, améliorent considérablement le taux de précision et de rappel. Ainsi, on peut actuellement obtenir de résultats allant de 60% à 80% de précision pour 40% à 60% de rappel[18].
Notes et références
- ↑ Gotel 1994, p. 94-101
- ↑ Ali 2011, p. 111-120
- ↑ Zou 2010, p. 119-146
- 1 2 Zou 2006, p. 265-272
- ↑ Zou 2007, p. 40-45
- ↑ Zou 2008, p. 157-163
- ↑ De Lucia 2011, p. 205-227
- ↑ Mader 2008, p. 49-58
- ↑ Sherba 2003, p. 32-39
- ↑ Østerbye 1996, p. 129-139
- ↑ Maletic 2009, p. 16-20
- ↑ Kagdi 2007, p. 145-154
- ↑ Gethers 2011, p. 133-142
- ↑ Poshyvanyk 2007, p. 420-432
- 1 2 Ali 2013, p. 725-741
- ↑ Ali 2013, p. 728-729
- 1 2 Ali 2013, p. 729
- ↑ Ali 2013, p. 737
Bibliographie
(en) N. Ali, Y.-G. Gueheneuc et G. Antoniol, « Trustrace: Mining Software Repositories to Improve the Accuracy of Requirement Traceability Links », IEEE Trans. Software Eng., , p. 725-741 (DOI 10.1109/TSE.2012.71, lire en ligne)
(en) N. Ali, Y.-G. Gueheneuc et G. Antoniol, « Trust-Based Requirements Traceability », Proc. 19th IEEE Int’l Conf. Program Comprehension, , p. 111-120 (DOI 10.1109/ICPC.2011.42, lire en ligne)
(en) G. Antoniol, G. Canfora, G. Casazza, A.D. Lucia et E. Merlo, « Recovering Traceability Links between Code and Documentation », IEEE Trans. Software Eng., vol. 28, no 10, , p. 970-983 (DOI 10.1109/TSE.2002.1041053, lire en ligne)
(en) A. De Lucia, M. Di Penta et R. Oliveto, « Help Improving Source Code Lexicon via Traceability and Information Retrieval », IEEE Trans. Software Eng., , p. 205-227 (DOI 10.1109/TSE.2010.89, lire en ligne)
(en) M. Gethers, R. Oliveto, D. Poshyvanyk et A.D. Lucia, « On Integrating Orthogonal Information Retrieval Methods to Improve Traceability Recovery », Proc. 27th IEEE Int’l Conf. Software Maintenance, , p. 133-142 (DOI 10.1109/ICSM.2011.6080780, lire en ligne)
(en) O.C.Z. Gotel et C.W. Finkelstein, « An Analysis of the Requirements Traceability Problem », Proc. First Int’l Conf. Requirements Eng., , p. 94-101 (DOI 10.1109/ICRE.1994.292398, lire en ligne)
(en) J.H. Hayes, A. Dekhtyar, S.K. Sundaram et S. Howard, « Helping Analysts Trace Requirements: An Objective Look », Proc. 12th IEEE Int’l Requirements Eng. Conf., , p. 249-259 (DOI 10.1109/RE.2004.26, lire en ligne)
(en) J.H. Hayes, G. Antoniol et Y.-G. Gueheneuc, « PREREQIR: Recovering Pre-Requirements via Cluster Analysis », Proc. 15th Working Conf. Reverse Eng., , p. 165-174 (DOI 10.1109/WCRE.2008.36, lire en ligne)
(en) H. Kagdi, J. Maletic et B. Sharif, « Mining Software Repositories for Traceability Links », Proc. 15th IEEE Int’l Conf. Program Comprehension, , p. 145-154 (DOI 10.1109/ICPC.2007.28, lire en ligne)
(en) A. Marcus et J.I. Maletic, « Recovering Documentation-to-Source-Code Traceability Links Using Latent Semantic Indexing », Proc. 25th Int’l Conf. Software Eng., , p. 125-135 (ISBN 0-7695-1877-X, lire en ligne)
(en) J.I. Maletic et M.L. Collard, « TQL: A Query Language to Support Traceability », Proc. ICSE Workshop Traceability in Emerging Forms of Software Eng., , p. 16-20 (DOI 10.1109/TEFSE.2009.5069577, lire en ligne)
(en) P. Mader, O. Gotel et I. Philippow, « Enabling Automated Traceability Maintenance by Recognizing Development Activities Applied to Models », Proc. 23rd IEEE/ACM Int’l Conf. Automated Software Eng., , p. 49-58 (DOI 10.1109/ASE.2008.15, lire en ligne)
(en) K. Østerbye et U. K. Wiil, « The Flag Taxonomy of Open Hypermedia Systems », Proceedings of the the seventh ACM conf. on Hypertext, , p. 129-139 (DOI 10.1145/234828.234841, lire en ligne)
(en) D. Poshyvanyk, Y.-G. Gueheneuc, A. Marcus, G. Antoniol et V. Rajlich, « Feature Location Using Probabilistic Ranking of Methods Based on Execution Scenarios and Information Retrieval », IEEE Trans. Software Eng., vol. 33, no 6, , p. 420-432 (DOI 10.1109/TSE.2007.1016, lire en ligne)
(en) S. A. Sherba, K. M. Anderson et M. Faisal, « A Framework for Mapping Traceability Relationships », 2nd Int’l Workshop on Traceability in Emerging Forms of Software Eng. at 18th IEEE Int’l Conf. on Automated Software Engineering, , p. 32-39 (DOI 10.1.1.128.1273, lire en ligne)
(en) X. Zou, R. Settimi et J. Cleland-Huang, « Phrasing in Dynamic Requirements Trace Retrieval », Proceedings of the 30th Annual Int’l Computer Software and Application Conf. (COMPSAC06), , p. 265-272 (DOI 10.1109/COMPSAC.2006.66, lire en ligne)
(en) X. Zou, R. Settimi et J. Cleland-Huang, « Term-based Enhancement Factors in Automated Requirements Traceability Retrieval », Proceedings of the 2nd Int’l Symposium on Grand Challenge in Traceability, , p. 40-45
(en) X. Zou, R. Settimi et J. Cleland-Huang, « Evaluating the Use of Project Glossaries in Automated Trace Retrieval », Proceedings of the 2008 Int’l Conf. on Software Eng. Research and Practice (SERP’08), , p. 157-163
(en) X. Zou, R. Settimi et J. Cleland-Huang, « Improving automated requirements trace retrieval: a study of term-based enhancement methods », Empirical Software Eng., , p. 119-146 (DOI 10.1007/s10664-009-9114-z, lire en ligne)
 Portail de l’informatique
Portail de l’informatique  Portail du logiciel
Portail du logiciel  Portail des sciences
Portail des sciences