Problème SAT
En informatique théorique, le problème SAT est un problème de décision défini par des formules logiques. Il s'agit, étant donné une formule de logique propositionnelle, de décider si cette formule possède une solution, c'est-à-dire s'il existe une assignation des variables rendant la formule vraie.
Ce problème est très important en théorie de la complexité. Il a été mis en lumière par le théorème de Cook, qui est à la base de la théorie de la NP-complétude et du problème P = NP. Ce modèle a aussi de nombreuses applications puisque de nombreux problèmes peuvent être modélisés par des formules logiques, notamment en planification classique, model checking, diagnostic, et jusqu'au configurateur d'un PC ou de son système d'exploitation.
Le terme SAT est repris de l'anglais où il est extrait de la locution boolean SATisfiability problem, qui signifie problème de satisfaisabilité booléenne.
Définitions
Clause et forme clausale
Une clause est une proposition de la forme 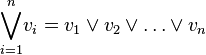 où les
où les 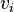 sont des littéraux (positifs ou négatifs).
sont des littéraux (positifs ou négatifs).
Une clause d'ordre n est une disjonction d'au plus n littéraux.
Une formule du calcul propositionnel est en forme normale conjonctive (ou forme clausale) d'ordre n si elle est une conjonction de clauses d'ordre n.
Le problème SAT
On dit qu'une formule logique sous forme normale conjonctive, parfois abrégé CNF sigle de l'anglais Conjunctive Normal Form, est satisfaisable[1] s'il est possible d'associer une valeur logique booléenne à chacune de ses variables afin que cette formule soit logiquement vraie.
Si la formule propositionnelle n'est pas sous forme normale conjonctive, il est nécessaire de la normaliser[2] pour que le problème soit qualifié de SAT. Généralement, la réponse à cette question fournit également un exemple d'assignation des variables pour laquelle la formule sous forme normale conjonctive soit logiquement vrai.
- Exemple
- Soit l'ensemble de variables
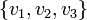 et la formule
et la formule 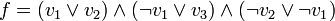 .
. -
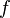 est satisfaisable puisque, si on pose
est satisfaisable puisque, si on pose 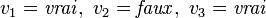 , alors est logiquement vrai.
, alors est logiquement vrai. - En revanche,
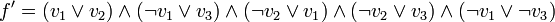 n'est pas satisfaisable, car
n'est pas satisfaisable, car 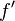 sera évalué comme faux quelles que soient les valeurs attribuées à
sera évalué comme faux quelles que soient les valeurs attribuées à 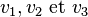 .
.
Déterminer si une formule sous forme normale conjonctive d'ordre n est satisfaisable est appelé problème de satisfaisabilité ou problème SAT d'ordre n, ou encore n-SAT. Selon la valeur de l'ordre n, et selon la possibilité de réduire cet ordre avec un algorithme de complexité simple, la complexité de ce problème obéira à des conditions différentes.
Complexité et restrictions
NP-complétude de 3-SAT
Le problème SAT général (d'ordre n non restreint et pouvant être arbitrairement grand mais fini) est un problème NP–complet d'après le théorème de Cook. En particulier, on ne connaît aucun algorithme déterministe polynomial pour le résoudre.
Le problème 3–SAT est lui aussi NP–complet. Pour le démontrer, il suffit de prouver que le problème SAT est polynomialement réductible à 3–SAT.
- Preuve
- On remarque que toute clause
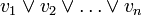 avec
avec 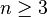 peut se mettre sous la forme :
peut se mettre sous la forme :
- Donc le problème SAT est polynomialement réductible à 3–SAT. On conclut que 3–SAT est NP–complet.
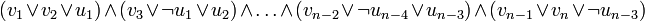
Tous les problèmes n–SAT avec n supérieur ou égal à 3 sont également des problèmes NP–complets.
- Exemple
- Soient
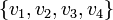 des variables propositionnelles.
des variables propositionnelles. - Déterminer si l'expression
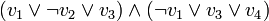 est satisfaisable est un problème 3–SAT.
est satisfaisable est un problème 3–SAT. - On conjecture que tout algorithme capable de résoudre un problème 3–SAT avec
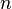 variables propositionnelles (même le « meilleur ») peut dans certains cas[Lesquels ?] devoir essayer un nombre de combinaisons d'assignations exponentiel en la valeur .
variables propositionnelles (même le « meilleur ») peut dans certains cas[Lesquels ?] devoir essayer un nombre de combinaisons d'assignations exponentiel en la valeur .
Le problème 2-SAT
2-SAT, d'après la définition, cherche à déterminer la satisfaisabilité d'une formule F du calcul propositionnel en forme normale conjonctive d'ordre 2. Ce problème est de classe 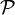 . Il n'est donc pas NP-complet, contrairement à SAT et 3-SAT (sous l'hypothèse
. Il n'est donc pas NP-complet, contrairement à SAT et 3-SAT (sous l'hypothèse 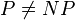 ). Il existe plusieurs algorithmes polynomiaux déterministes pour résoudre le problème 2-SAT.
). Il existe plusieurs algorithmes polynomiaux déterministes pour résoudre le problème 2-SAT.
- Exemple
- Intéressons nous plus particulièrement à celui présenté par Aspvall, Plass et Tarjan en 1979[3].
- Une clause d'ordre deux
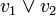 est équivalente aux implications
est équivalente aux implications 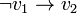 et
et  .
. - Pour résoudre 2-SAT, on construit le graphe orienté G = (S,A) dual (appelé graphe 2-SAT) selon les deux règles suivantes :
- Les sommets S correspondent aux différentes variables propositionnelles
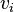 (ou leurs négations
(ou leurs négations 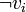 ) de la formule considérée.
) de la formule considérée. - On associe ensuite à chaque clause les deux arcs
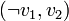 et
et 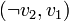 pour former l'ensemble A.
pour former l'ensemble A.
- Les sommets S correspondent aux différentes variables propositionnelles
- F est satisfaisable si et seulement si pour chaque variable propositionnelle
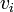 de F, les sommets et
de F, les sommets et 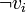 du graphe 2-SAT sont dans deux composantes fortement connexes distinctes.
du graphe 2-SAT sont dans deux composantes fortement connexes distinctes. - L'algorithme de Tarjan permet de calculer les composantes fortement connexes d'un graphe orienté en
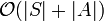 , donc 2-SAT est bien de classe
, donc 2-SAT est bien de classe 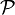 .
.
Un autre résultat intéressant, obtenu par Christos Papadimitriou en 1994, concerne la complexité en termes d'espace du problème 2-SAT. Celui-ci est complet pour la classe de complexité NL.
Algorithmes de SAT
La plus évidente des méthodes pour résoudre un problème SAT est de parcourir la table de vérité du problème, mais la complexité est alors exponentielle par rapport au nombre de variables.
Méthode systématique
Pour prouver la satisfaisabilité du CNF 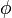 , il suffit de choisir une variable
, il suffit de choisir une variable 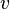 et de prouver récursivement la satisfaisabilité de
et de prouver récursivement la satisfaisabilité de 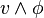 ou
ou 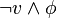 . La procédure est plus facile récursivement puisque
. La procédure est plus facile récursivement puisque 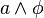 avec
avec  ou
ou 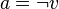 peut souvent se simplifier. L'appel récursif construit ainsi un arbre binaire de recherche.
peut souvent se simplifier. L'appel récursif construit ainsi un arbre binaire de recherche.
Généralement, il existe à chaque nœud des clauses unitaires (la CNF est de la forme 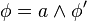 ), qui permettent de réduire fortement l'espace de recherche.
), qui permettent de réduire fortement l'espace de recherche.
- Exemple
- Considérons la CNF :
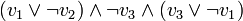 .
.
- La deuxième clause (
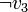 ) est unitaire et permet d'obtenir immédiatement
) est unitaire et permet d'obtenir immédiatement 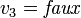 . On peut remplacer les valeurs de
. On peut remplacer les valeurs de 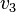 dans ce CNF. Cela donne :
dans ce CNF. Cela donne :
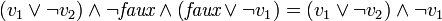 .
.
- À nouveau, on a une clause unitaire, et on obtient
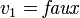 . Puis, par propagation, on obtient
. Puis, par propagation, on obtient 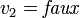 .
.
Dans cet exemple, on a trouvé les valeurs des trois variables sans même développer l'arbre de recherche. De manière générale, on peut réduire fortement l'espace de recherche. D'autre part, si une variable 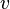 apparaît toujours positivement dans la CNF , alors on peut poser
apparaît toujours positivement dans la CNF , alors on peut poser 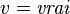 puisque est satisfaisable si et seulement si
puisque est satisfaisable si et seulement si 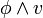 est satisfaisable (et de même si la variable apparaît négativement). Ainsi, dans l'exemple précédent,
est satisfaisable (et de même si la variable apparaît négativement). Ainsi, dans l'exemple précédent, 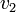 n'apparaît que négativement et l'assignation
n'apparaît que négativement et l'assignation 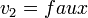 peut être effectuée. Remarquons que cette affectation permet d'accélérer la découverte d'une solution mais que des solutions pourraient exister en effectuant l'assignation contraire.
L'algorithme DPLL (Davis, Putnam[4], Davis, Logemann, Loveland[5]) se base sur ces idées.
peut être effectuée. Remarquons que cette affectation permet d'accélérer la découverte d'une solution mais que des solutions pourraient exister en effectuant l'assignation contraire.
L'algorithme DPLL (Davis, Putnam[4], Davis, Logemann, Loveland[5]) se base sur ces idées.
Le choix de la variable à développer est très important pour les performances des algorithmes SAT. On choisit généralement les variables qui apparaissent le plus souvent, si possible dans des clauses de taille 2.
Apprentissage de clauses par conflits
Le principe des solveurs de type CDCL (Conflict-Driven Clause Learning) est d'utiliser un mécanisme pour apprendre de nouvelles clauses en cours de recherche, puis d'utiliser un maximum toutes les informations apprises dans l'espoir d'améliorer le temps de recherche. D'un point de vue pratique, cette méthodologie est très efficace pour résoudre des problèmes concrets[6]. L'apprentissage de clauses est le suivant : lorsqu'un conflit apparaît lors de la recherche, c'est-à-dire lorsqu'une assignation partielle est démontrée non cohérente avec l'ensemble des clauses, on peut isoler un sous-ensemble de ces assignations et un sous-ensemble de ces clauses, qui sont responsables du conflit (les assignations ne sont pas cohérentes avec les clauses). L'apprentissage de clause permet deux choses. Premièrement, il permet d'éviter de refaire plusieurs fois les mêmes erreurs dans l'arbre de recherche. Deuxièmement, la close apprise sera en contradiction avec l'état de l'arbre de recherche. De ce fait, il sera nécessaire de réaliser un retour en arrière (backtracking) pour s'assurer qu'au moins un de ces littéral soit vrai.
Il existe différentes méthodes pour générer de nouvelles clauses à partir d'une inconsistance locale.
Méthode naïve
Soit l'instance à résoudre la formule 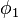 suivante :
suivante :
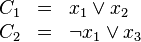
et l'interprétation partielle 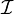 définie par:
définie par: 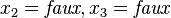 . Cette interprétation mène à un conflit car
. Cette interprétation mène à un conflit car 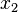 implique que
implique que 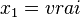 , tandis que
, tandis que 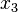 implique que
implique que 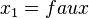 . Pour générer une clause représentant ce conflit, il est possible de prendre la négation de l'interprétation :
. Pour générer une clause représentant ce conflit, il est possible de prendre la négation de l'interprétation : 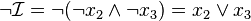 . Cependant, cette méthode possède un inconvénient majeur: la clause taille de la clause est entièrement déterminée par toute l'interprétation. Or, certaines parties de l'interprétation peuvent complètement indépendante du conflit que l'on souhaite représenter. En effet, ajoutons à l'instance les formules:
. Cependant, cette méthode possède un inconvénient majeur: la clause taille de la clause est entièrement déterminée par toute l'interprétation. Or, certaines parties de l'interprétation peuvent complètement indépendante du conflit que l'on souhaite représenter. En effet, ajoutons à l'instance les formules: 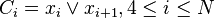 et soit l'interprétation courante
et soit l'interprétation courante 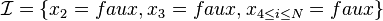 . Le conflit provient des deux premières clauses et donc, des valeurs de et . Or, la clause générée par la négation de l'interprétation prendra en compte toutes les variables à l'exception de x_1. De ce fait, la clause sera inutilement longue.
. Le conflit provient des deux premières clauses et donc, des valeurs de et . Or, la clause générée par la négation de l'interprétation prendra en compte toutes les variables à l'exception de x_1. De ce fait, la clause sera inutilement longue.
Analyse des conflits
Lorsque cette méthode est utilisée, un graphe est créé permettant de représenter l'origine de la propagation, appelé graphe d'implication. Les nœuds représentent les littéraux vrais. Il existe deux types de nœuds : les nœuds carrés dont la valeur du littéral provient d'un choix arbitraire et les nœuds ronds dont la valeur provient d'une propagation. À chaque nœud est également associée une information : le niveau du nœud en question. Ce niveau est défini par le nombre de littéraux choisis avant de réaliser la propagation s'il y a eu propagation. Sinon, le niveau est défini par le nombre de littéraux choisis, littéral courant compris. Les arcs relient entre eux les littéraux faisant partie d'une clause servant à la propagation. La destination d'un arc est le littéral propagé, la/les source(s) étant les autres littéraux de la clause. Soit l'instance à résoudre la formule 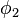 suivante :
suivante :
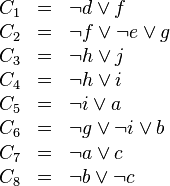
accompagné de l'interprétation à laquelle les niveaux des différents littéraux ont été spécifiés 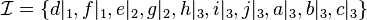 ainsi que le littéral menant à l’inconsistance :
ainsi que le littéral menant à l’inconsistance : 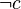 . Alors, il est possible d'en tirer le graphe suivant.
. Alors, il est possible d'en tirer le graphe suivant.
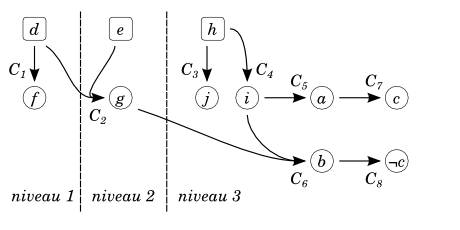
Grâce à ce graphe, il est possible de créer une clause représentant la cause du conflit. La méthode employée est la suivante : on commence par créer la résolvante  des clauses menant à un conflit. Puis tant qu'il reste plus d'un littéral du niveau courant, une nouvelle résolvante
des clauses menant à un conflit. Puis tant qu'il reste plus d'un littéral du niveau courant, une nouvelle résolvante  est créée entre la résolvante courante
est créée entre la résolvante courante 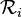 et la cause d'un des littéraux du niveau courant. Sur notre exemple, cela donnera (où
et la cause d'un des littéraux du niveau courant. Sur notre exemple, cela donnera (où 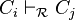 représente la résolution entre la clause
représente la résolution entre la clause 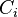 et la clause
et la clause 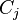 )
)
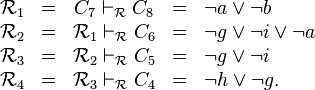
{kind=link}
Retour en arrière non chronologique
Une fois la clause apprise, celle-ci sera utilisée pour le retour en arrière. L'idée derrière le retour en arrière non chronologique est qu'un retour en arrière sera effectué de manière à ce que l'état des assignations soit tel qu'il ne reste qu'un seul littéral non assigné. Ainsi, grâce à la clause apprise il sera possible de continuer les différentes propagations alors que cela n'était plus possible sans elle.
Si l'on reprend l'exemple présenté dans la section analyse de conflit, la clause apprise 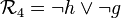 nous procure deux littéraux. Les niveaux des variables correspondantes sont: variable
nous procure deux littéraux. Les niveaux des variables correspondantes sont: variable 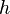 = 3, variable
= 3, variable 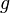 = 2. Pour savoir à quel niveau il est nécessaire de revenir en arrière, il faut regarder le niveau le plus profond (le niveau
= 2. Pour savoir à quel niveau il est nécessaire de revenir en arrière, il faut regarder le niveau le plus profond (le niveau 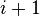 est plus profond que le niveau
est plus profond que le niveau 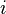 ) des variables d'un niveau plus haut que le niveau actuel. Étant donné que la clause apprise ne contient que deux littéraux, il n'existe qu'un seul niveau différent du niveau actuel: le niveau 2. Un retour en arrière est donc effectué jusqu'à ce niveau et laisse donc comme interprétation
) des variables d'un niveau plus haut que le niveau actuel. Étant donné que la clause apprise ne contient que deux littéraux, il n'existe qu'un seul niveau différent du niveau actuel: le niveau 2. Un retour en arrière est donc effectué jusqu'à ce niveau et laisse donc comme interprétation 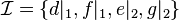 . Or, avec une telle interprétation, la clause apprise ne contient bien qu'une seule variable non affectée : tandis que l'autre est affectée de telle manière à ce que le littéral
. Or, avec une telle interprétation, la clause apprise ne contient bien qu'une seule variable non affectée : tandis que l'autre est affectée de telle manière à ce que le littéral 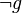 soit faux. Cela implique la nécessité d'une propagation de la variable à la valeur faux.
soit faux. Cela implique la nécessité d'une propagation de la variable à la valeur faux.
Bien que dans cet exemple le retour en arrière ne s'effectue que sur un seul niveau, il est possible que celui-ci monte de plusieurs niveau d'un coup. En effet, imaginons que nous puissions ajouter N niveaux entre le niveau 2 et le niveau 3 où toutes les variables qui y apparaissent soient de nouvelles variables. Puisque ces niveaux n'auraient pas d'impact sur l'ancien niveau 3, le retour en arrière remonterait d'un coup ces N+1 niveaux.
Approches prospectives
L'approche prospective consiste à prospecter l'arbre de recherche pour découvrir des assignations certaines. Ainsi, étant donné un CNF , étant donnée une variable non instanciée , on prospecte les CNFs et 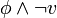 . Si les deux CNFs conduisent à l'instanciation de la même variable
. Si les deux CNFs conduisent à l'instanciation de la même variable 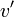 avec la même valeur, alors l'instanciation peut se faire dès la CNF .
avec la même valeur, alors l'instanciation peut se faire dès la CNF .
- Exemple
- Considérons la CNF
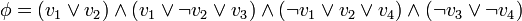 . Nous nous intéressons ici à la variable et prospectons la variable
. Nous nous intéressons ici à la variable et prospectons la variable 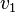 .
. - Considérons l'assignation
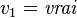 . On obtient
. On obtient 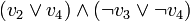 et donc l'assignation
et donc l'assignation 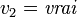 (puisque cette variable apparaît uniquement positivement).
(puisque cette variable apparaît uniquement positivement). - Considérons l'assignation
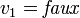 . On obtient
. On obtient 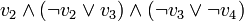 et donc l'assignation par clause unitaire.
et donc l'assignation par clause unitaire. - Dans tous les cas, on obtient et il est donc possible d'effectuer cette assignation dès la CNF .
Rappelons que la complexité du problème SAT vient de la taille exponentielle de l'arbre de recherche par rapport au nombre de variables. La prospection permet de réduire fortement ce nombre de variables dès la racine (ou à n'importe quel nœud de l'arbre) avec une complexité supplémentaire relativement faible eu égard à la diminution de l'arbre de recherche.
Recherche locale
Partant d'une assignation de toutes les variables, on cherche à modifier certaines valuations de façon à réduire le nombre de clauses non satisfaites. Cet algorithme souffre de plusieurs défauts : il peut tomber dans des minima locaux et il est incapable de prouver la non-satisfaisabilité, mais il s'avère très efficace dans les problèmes non structurés (c'est-à-dire souvent les problèmes générés aléatoirement). En cas d'échec après un temps long, il est possible de choisir une nouvelle assignation aléatoire pour éviter les minima locaux.
Principales implémentations
- zChaff (Moskewicz, Madigan, Zhao, Zhang, 2001)
- Siege (Ryan, 2003)
- MiniSAT (Eén et Sörensson, 2005-)
- ManySAT (Hamadi, Jabbour et Sais, 2008-)
- Glucose [7] (Audemard et Simon, 2009-), basé sur Minisat
Applications
Il est possible de traduire certains problèmes d'intelligence artificielle en une formule de logique propositionnelle et d'utiliser les algorithmes SAT pour résoudre efficacement ces problèmes.
Diagnostic
Le diagnostic de systèmes statiques consiste à déterminer si un système a un comportement défectueux étant donnée l'observation des entrées et sorties du système. Le modèle du système peut être traduit en un ensemble de contraintes (disjonctions) : pour chaque composant  du système, une variable
du système, une variable 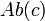 est créée qui est évaluée à vraie si le composant a un comportement anormal (Abnormal). Les observations peuvent être également traduites par un ensemble de disjonctions. L'assignation trouvée par l'algorithme de satisfaisabilité est un diagnostic.
est créée qui est évaluée à vraie si le composant a un comportement anormal (Abnormal). Les observations peuvent être également traduites par un ensemble de disjonctions. L'assignation trouvée par l'algorithme de satisfaisabilité est un diagnostic.
Planification classique
Le problème de planification classique consiste à trouver une séquence d'actions menant d'un état du système à un ensemble d'états. Étant donnée une longueur maximale du plan et un ensemble 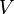 de variables d'état booléennes permettant de décrire l'état du système, on crée les variables propositionelles
de variables d'état booléennes permettant de décrire l'état du système, on crée les variables propositionelles 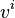 pour tout
pour tout 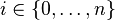 et toute variable
et toute variable 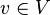 . La variable est vraie si la variable d'état est vraie après l'action numéro . On crée également les variables
. La variable est vraie si la variable d'état est vraie après l'action numéro . On crée également les variables 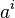 pour tout
pour tout 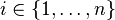 et toute action
et toute action 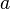 . La variable est vraie si l'action numéro est . Il est alors possible de transformer le modèle du système en un ensemble de clauses. Par exemple, si l'action fait passer la variable
. La variable est vraie si l'action numéro est . Il est alors possible de transformer le modèle du système en un ensemble de clauses. Par exemple, si l'action fait passer la variable 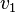 à vrai lorsque celle-ci est fausse, alors la CNF contiendra une clause
à vrai lorsque celle-ci est fausse, alors la CNF contiendra une clause 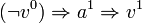 (ce qui est traduit par la clause
(ce qui est traduit par la clause 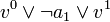 ). L'assignation trouvée par l'algorithme de satisfaisabilité peut être immédiatement traduite en plan.
). L'assignation trouvée par l'algorithme de satisfaisabilité peut être immédiatement traduite en plan.
La planification classique par SAT est très efficace si on connaît la longueur n du plan[réf. nécessaire]. Si cette valeur n'est pas connue, on peut chercher des plans pour une valeur incrémentale, ce qui est parfois coûteux (notamment parce que la CNF est non satisfaisable jusqu'à n – 1).
Model checking
Une approche semblable a été utilisée pour le model checking (vérification de propriétés d'un modèle). La principale différence est que le model checking s'applique à des trajectoires de longueur infinie contrairement à la planification. Cependant, si l'espace d'états du système est fini, toute trajectoire infinie boucle à un certain point et on peut borner la taille des trajectoires qu'il est nécessaire de vérifier. Le bounded model checking tire parti de cette propriété pour transformer le problème de model checking en un certain nombre de problèmes de satisfaisabilité.
Cryptographie
La complexité du problème SAT est une composante essentielle de la sécurité de tout système de cryptographie.
Par exemple une fonction de hachage sécurisée constitue une boîte noire pouvant être formulée en un temps et un espace fini sous la forme d'une conjonction de clauses normales, dont les variables booléennes correspondent directement aux valeurs possibles des données d’entrée de la fonction de hachage, et chacun des bits de résultat devra répondre à un test booléen d'égalité avec les bits de données d’un bloc de données d’entrées quelconque. Les fonctions de hachages sécurisées servent notamment dans des systèmes d'authentification (connaissance de données secrètes d’entrée ayant servi à produire la valeur de hachage) et de signature (contre toute altération ou falsification « facile » des données d’entrée, qui sont connues en même temps que la fonction de hachage elle-même et de son résultat).
La sécurité de la fonction de hachage dépend de la possibilité de retrouver un bloc de données d‘entrée arbitraire (éventuellement différent du bloc secret de données pour lequel une valeur de hachage donnée a été obtenue) permettant d'égaliser la valeur binaire retournée par la fonction de hachage. Une méthode d'exploration systématique de toutes les valeurs possibles des données d‘entrée et pour lesquelles on applique la fonction de hachage comme un oracle, permet effectivement de satisfaire à la question de une valeur de hachage égale à celle cherchée, mais sa complexité algorithmique sera exponentielle (en fonction de la taille maximale en bits des données d’entrée de la fonction de hachage).
Chercher à égaliser une valeur de hachage avec des variables d'entrée de valeur inconnue constitue un problème SAT (et comme en pratique les données d’entrée de la fonction de hachage sont constituées de nombreux bits, ce sera un problème n-SAT avec n assez élevé (et en tout cas supérieur ou égal à 3). On sait alors que ce problème est réductible en temps polynomial à un problème 3–SAT, qui est NP-complet.
La sécurité de la fonction de hachage sera fortement liée au fait de l'impossibilité de la réduire plus simplement (que par un algorithme NP-complet de complexité suffisante) en réduisant la forme conjonctive des clauses qui la définissent simplement, pour y isoler des sous-ensembles de variables d’entrées de taille plus restreinte, mais suffisante pour déterminer une partie du résultat de la fonction de hachage dont l’ordre n sera alors très inférieur, et pour ne plus avoir à explorer que les valeurs possibles de ces seuls sous-ensembles de variables pour satisfaire la condition d'égalité du résultat, sans avoir à tester toutes les autres variables dont la valeur peut être fixée arbitrairement à certaines valeurs déterminées par un algorithme plus simple (apprentissage de clauses, approches prospectives ci-dessus).
Notes et références
- ↑ « Satisfaisable », sur CNRTL.
- ↑ Cela ne modifie pas la nature du problème, notamment par restriction. En effet, « toute formule du calcul propositionnel est logiquement équivalente à au moins une formule sous forme normale conjonctive et à au moins une formule sous forme normale disjonctive[réf. nécessaire] ».
- ↑ (en) Bengt Aspvall, Michael F. Plass, et Robert E. Tarjan, « A linear-time algorithm for testing the truth of certain quantified boolean formulas », Information Processing Letters, 8, p. 121-123 (1979), [lire en ligne].
- ↑ (en) Martin Davis et Hillary Putnam, « A Computing Procedure for Quantification Theory », Communications of the ACM, 7, p. 201-215 (1960) [lire en ligne]
- ↑ (en) Martin Davis, George Logemann et Donald Loveland, « A machine Program for Theorem Proving », Communications of the ACM, 5, p. 394-397 (1962), [lire en ligne]
- ↑ Classement des solveurs lors du SAT Challenge 2012, catégorie Application | Sat Challenge 2012
- ↑ Voir
Voir aussi
Bibliographie
- René Cori et Daniel Lascar, Logique mathématique I. Calcul propositionnel, algèbres de Boole, calcul des prédicats [détail des éditions]
- J.-M. Alliot, T. Schiex, P.Brisset et F. Garcia, Intelligence artificielle & informatique théorique, Cépaduès, 2002 (ISBN 2-85428-578-6)
- L. Sais, Problème SAT : Progrès et Défis, 2008 (ISBN 2746218860)
Article connexe
- Problème 3-SAT
- Formule booléenne quantifiée vraie (en)
Lien externe
http://www.satcompetition.org/
 Portail de l'informatique théorique
Portail de l'informatique théorique  Portail de la logique
Portail de la logique