{kind=link}
Index (base de données)
En informatique, dans les bases de données, un index est une structure de données utilisée et entretenue par le système de gestion de base de données (SGBD) pour lui permettre de retrouver rapidement les données. L'utilisation d'un index simplifie et accélère les opérations de recherche, de tri, de jointure ou d'agrégation effectuées par le SGBD.
L’index placé sur une table va permettre au SGBD d'accéder très rapidement aux enregistrements, selon la valeur d'un ou plusieurs champs.
Principe
Un index est une structure entretenue automatiquement, qui permet de localiser facilement des enregistrements dans un fichier. L'utilisation des index est basée sur l'observation suivante: pour trouver un livre dans une bibliothèque, au lieu d'examiner un par un chaque livre, il est plus rapide de consulter le catalogue où ils sont classés par thème, auteur et titre[1]. Chaque entrée d'un index comporte une valeur extraite des données et un pointeur sur son emplacement d'origine. Un enregistrement peut être ainsi facilement retrouvé en recherchant sa localisation dans l'index[2].
Un index peut être ordonné, haché, dense ou épars[2]:
- Un index ordonné contient une liste de valeurs extraites d'une table et triés.
- Dans un index haché les valeurs sont transformées par une fonction de hachage.
- Dans un index dense, la totalité des enregistrements d'une table sont référencés.
- Dans un index épars seule une partie des enregistrements est référencée.
L'index primaire d'une table est le premier qui est utilisé pour localiser les enregistrements. Une table peut également contenir des index secondaires en complément de l'index primaire[2]. Chaque table peut comporter un ou plusieurs index. Un index peut être issu d'un seul champ ou peut combiner plusieurs champs[1].
Technique

Les index sont utilisés par les SGBD pour de nombreuses opérations. Les index facilitent les opérations de tri, de recherche, de regroupement et de jointure[1]. La structure la plus courante des index est l'arbre B[3]. D'autres structures existent mais sont rarement utilisées - ISAM, les tables de hachage ou les bitmaps[3].
- structure en arbre: un tronc auquel sont attachées des branches avec des ramifications et des feuilles au bout. Toutes les recherches sont effectuées en partant du tronc. En recherchant parmi les branches celle qui contient la valeur à trouver, jusqu'à avoir atteint une feuille[2].
Pour accélérer les opérations, les arbres d'index sont enregistrés en un bloc comportant un très grand nombre de ramifications: Les disques durs, sur lesquels sont enregistrés les index, lisent les données par bloc de plusieurs kilooctets et le temps nécessaire pour lire un bloc est généralement très inférieur au temps nécessaire pour le localiser. Avec cette construction, la recherche d'un enregistrement dans un lot de plusieurs millions nécessite alors seulement 2 ou 3 opérations[3].
Les index peuvent être ajoutés par une commande SQL[1]. L'existence d'index est cruciale pour accélérer les opérations de manipulation de données. L'utilisation inadéquate des index est la principale cause de déception[4]. Le système de gestion de base de données (abr. SGBD) ne trouvera pas les index qui sont nécessaires pour effectuer efficacement les opérations qui lui sont demandées[4]. Les raisons de l'utilisation inadéquate sont que la documentation des SGBD concernant l'utilisation des index est souvent vague et succincte, et met en avant leurs inconvénients plus que leurs avantages[4].
Les index sont en particulier exploités par l´optimiseur de requêtes:
- L'optimiseur est le composant des SGBD qui recherche la manière la plus économique d'exécuter une requête. L'optimiseur examine les différents scénarios possibles et estime le nombre d'opération nécessaires pour chaque scénario, puis opte pour le scénario qui en demande le moins. Le nombre d'opérations nécessaires dépend de la présence d'index, ainsi que du nombre de lignes de la table et de la répartition des valeurs[5].
Types d'index
- La structure la plus courante pour les index est l'arbre B (B-tree). En stockant les différentes valeurs du champ dans un arbre équilibré, le SGBD pourra hiérarchiser les enregistrements d'après un champ dont la plage de valeurs est infinie (ou presque).
- Un autre type d'index est l'index bitmap. Il consiste en une simple table indiquant, pour chaque valeur possible du champ, la liste des enregistrements ayant cette valeur pour ce champ.
- Cependant, pour être efficace, il nécessite que le SGBD puisse accéder directement à une valeur donnée. Il n'est donc applicable que sur les colonnes pour lesquelles le nombre de valeurs est limité et ordonné.
- On trouve également des index par table de hachage. L'inconvénient majeur d'un tel index est de ne permettre que les sélections par égalité, puisqu'il ne conserve pas la notion d'ordre. Si n est le nombre d'enregistrements d'une table, l'utilisation d'une table de hachage équilibrée peut permettre de réduire le nombre d'enregistrements à parcourir à
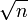 , la racine carrée de n (la table étant alors composée de valeurs de hachage accédant chacune à enregistrements). La même remarque sur l'efficacité existe pour l'index bitmap : le SGBD doit pouvoir accéder directement à une valeur de hachage donnée, sans avoir à parcourir la liste des valeurs de hachage possibles.
, la racine carrée de n (la table étant alors composée de valeurs de hachage accédant chacune à enregistrements). La même remarque sur l'efficacité existe pour l'index bitmap : le SGBD doit pouvoir accéder directement à une valeur de hachage donnée, sans avoir à parcourir la liste des valeurs de hachage possibles.
Impacts sur les performances en modification
Lors de l'insertion ou de la mise à jour d'un enregistrement de la base, il y a une légère dégradation des performances : le SGBD doit en effet mettre à jour les index pour qu'ils continuent à refléter l'état des enregistrements. Pour cette raison, on s'attachera, lors de la conception d'une base de données, à définir uniquement les index qui seront utilisés par le système. Ceux-ci ne seront d'ailleurs bien repérés que par une analyse du système (et notamment des mécanismes d'interrogation de la base) en vue de son optimisation.
Autres formes d'indexation
D'autres types de structures offrent des fonctionnalités d'indexation :
- Tables clusterisées
- Vue matérialisée
Remarque sur les index multi-colonnes
Dans le cas d'un index multi-colonnes, le SGBD peut "décider" de l'utiliser partiellement, dans l'ordre des colonnes de l'index. En d'autres termes, un index sur des colonnes (c1,c2,c3,c4) peut être utilisé comme un index (c1,c2,c3), (c1,c2) ou (c1).
Notes et références
- 1 2 3 4 (en)Carlos Coronel, Steven Morris et Peter Rob,Database Systems: Design, Implementation, and Management,Cengage Learning - 2012,(ISBN 9781111969608)
- 1 2 3 4 (en)S. K. Singh,Database Systems: Concepts, Design and Applications,Pearson Education India - 2009,(ISBN 9788177585674)
- 1 2 3 (en)Gavin Powell,Beginning Database Design,John Wiley & Sons - 2006,(ISBN 9780764574900)
- 1 2 3 (en)Tapio Lahdenmaki et Mike Leach,Relational Database Index Design and the Optimizers,John Wiley & Sons - 2005,(ISBN 9780471721369)
- ↑ (en)Ken England, Gavin JT Powell, Microsoft SQL Server 2005 Performance Optimization and Tuning Handbook,Digital Press - 2011,(ISBN 9780080554082)
Liens externes
- (en) Comment MySQL utilise les index
Voir aussi
 Portail de l’informatique
Portail de l’informatique  Portail des bases de données
Portail des bases de données